Informed by 2,500+ business and technology experts; 500,000+ client interactions; 27,000+ vendor briefings; and 715,000+ vetted peer reviews, Gartner expert guidance gives you the trusted insights you need for stronger performance on your mission-critical priorities.
- Gartner client? Log in for personalized search results.
Gartner Research
Use Data Twins to Accelerate Delivery of AI-Ready Data
Published: 14 October 2025
Summary
As data volumes grow, data and analytics leaders increasingly struggle to efficiently create and manage AI-ready data. By implementing a data twin as a data product, you apply formal statistical sampling techniques in a governed, flexible, and reusable way. This method produces a representative subset of the full data population, supporting reliable inference for exploration, estimation, and hypothesis testing — essential for guaranteeing data representativeness in AI use cases.
Included in Full Research
Analysts:
Access Insights
Already a Gartner client?
Explore other complimentary insights you might like
Learn more about Gartner
- Insights
- AskGartner
- Dedicated Support
- Diagnostics
- Experts 1:1
- Technology Tools
- Conferences
Enabling faster, smarter business decisions

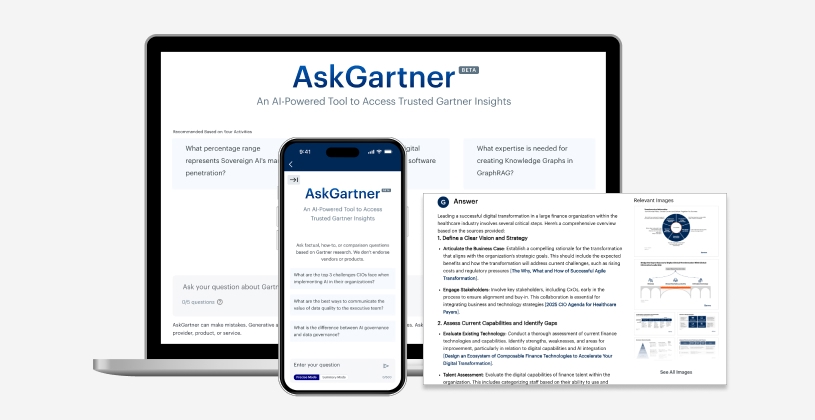
Proprietary insights, at your fingertips
Explore AskGartner, the only AI-powered tool that gives you access to the proprietary Gartner insights trusted by C-Level executives and their teams. Get faster answers, tailored outputs and the confidence you need to take action in minutes.
Former CxOs in your corner
Gartner Executive Partners are deeply accomplished former practitioners who have spent time in your role, tackling the very challenges you’re facing now. Dedicated to your unique needs, they provide strategic and tailored guidance, including bespoke tools, and can even foster exclusive peer connections — all designed to help drive your business and personal goals.

Improving your functional effectiveness to drive business performance
From comprehensive functional diagnostics like Gartner Score to leadership guides like Executive FastStart™, our proven suite of tools helps you assess current performance, identify functional gaps, implement best practices and accelerate improvements and achieve measurable business outcomes.
Crucial conversations with leading experts
Confidential conversations between clients and Gartner experts enable you to drill down into specific initiatives, needs or challenges. Our experts form a global team of seasoned analysts, advisors and practitioners with backgrounds spanning industry, academia and executive roles to deliver both deep subject matter expertise and real-world perspective.

Tools to scope, select and buy technology with confidence
Use a Gartner Hype Cycle™ report to gauge emerging trends; a Gartner Magic Quadrant™ tool to compare vendors; Proposal Reviews to optimize vendor costs. These are just some of the Gartner tools you can leverage to make confident technology-investment decisions and achieve better business outcomes.

Real insights. Real expertise. Real people.
From our must-attend conferences to local Gartner C-level Communities and our unrivaled Gartner Peer Community™, connect with Gartner experts, best-in-class solution providers and verified peers to refine your organization’s strategies, accelerate growth, reduce risk and gain a competitive edge.

Attend a Conference
Experience Information Technology conferences
With exclusive insights from Gartner experts on the latest trends, sessions curated for your role and unmatched peer networking, Gartner conferences help you accelerate your priorities.
23 – 24 Feb 2026
Gartner CIO Leadership Forum
Phoenix, AZ

© 2026 Gartner, Inc. and/or its affiliates. All rights reserved. Gartner is a registered trademark of Gartner, Inc. and its affiliates. This publication may not be reproduced or distributed in any form without Gartner's prior written permission. It consists of the opinions of Gartner's business and technology insights organization, which should not be construed as statements of fact. While the information contained in this publication has been obtained from sources believed to be reliable, Gartner disclaims all warranties as to the accuracy, completeness or adequacy of such information. Although Gartner business and technology insights may address legal and financial issues, Gartner does not provide legal or investment advice and its insights should not be construed or used as such. Your access and use of this publication are governed by Gartner’s Usage Policy. Gartner prides itself on its reputation for independence and objectivity. Its insights are produced independently by its business and technology insights organization without input or influence from any third party. For further information, see Guiding Principles on Independence and Objectivity. Gartner publications and other content may not be used as input into or for the training or development of generative artificial intelligence, machine learning, algorithms, software or related technologies.