AI-ready data is a must to capture the promise of AI efforts. Be clear what it is — and take these five steps to prepare.
- Gartner client? Log in for personalized search results.
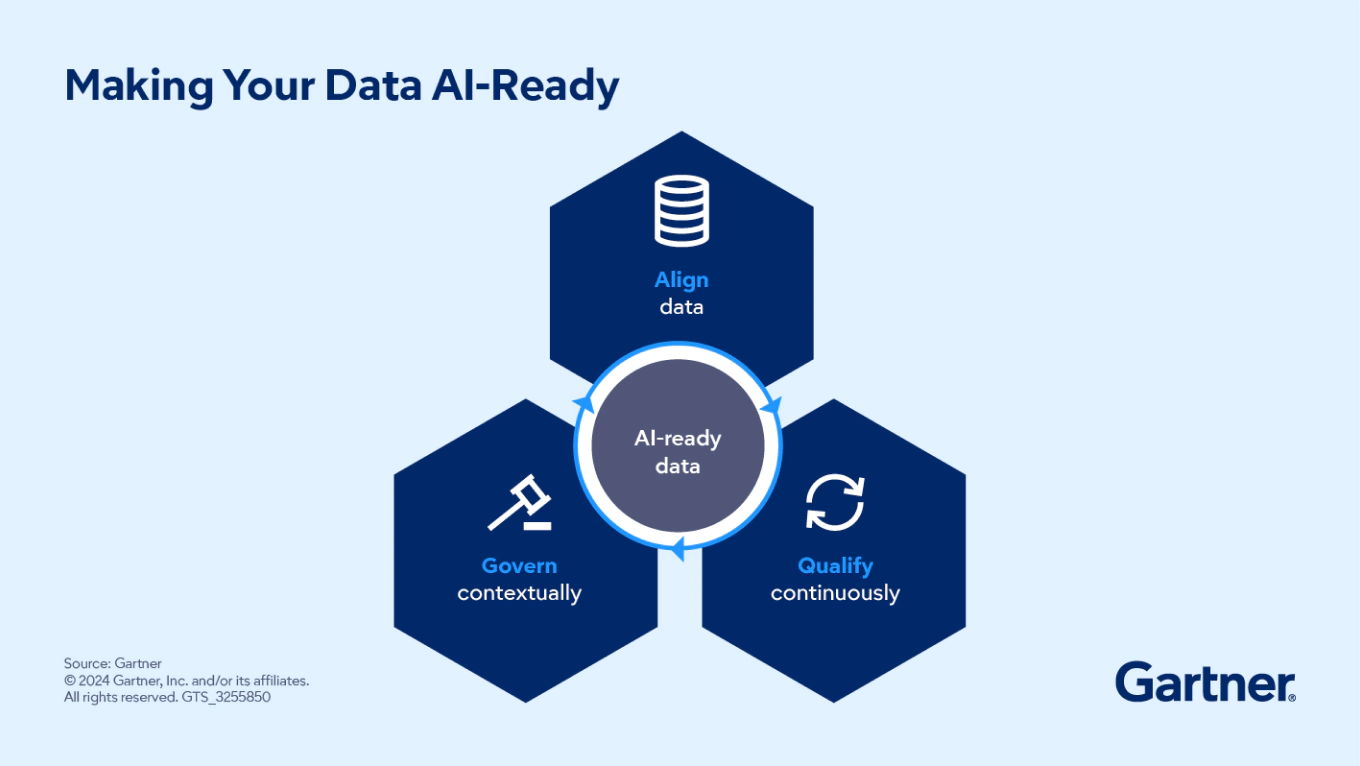
AI-ready data has specific requirements; use a roadmap to stay on track
Data and analytics leaders must prove their organization’s data is ready to be used in an ever-growing number of AI initiatives, but vast differences exist between AI-ready data requirements and traditional data management. To bridge that gap, Gartner recommends the following steps:
Assess your data needs depending on the AI use cases.
Present requirements to the board and gain buy-in from them.
Evolve data management practices.
Extend the data management ecosystem.
Scale and govern.
This roadmap will ensure your data is ready for use in the specific AI initiatives you plan to pursue and keeps stakeholders aligned around what it really means for data to be AI-ready.
You may also like: Explore Get AI Ready — What IT Leaders Need to Know and Do to learn more about mapping AI opportunities use cases.
What does it mean for data to be AI-ready?
You can prove your data is ready to meet AI requirements by aligning data to use cases, qualifying it and demonstrating appropriate governance. Asking these three questions can help.
Does our organization’s data align with use-case requirements?
Every AI use case should describe what data it needs, which will also depend on the AI technique that is used. This may not be fully defined upfront but will emerge as the data is used and the AI requirements are met. Delve into requirements, such as:
AI techniques: Different AI techniques, such as generative AI (GenAI) or simulation models, have unique data requirements.
Quantification: Ensure sufficient data volume, considering patterns like seasonality.
Semantics and labeling: Proper annotation and labeling, especially for images and videos, are crucial.
Quality: Data must meet quality standards specific to the AI use case, even if it includes errors or outliers.
Trust: Data sources and pipelines must be reliable.
Diversity: Include diverse data sources to avoid bias.
Lineage: Maintain transparency about data origins and transformations.
For stronger, faster AI outcomes, use Gartner’s proprietary AI Use Case Insights tool to explore, evaluate and prioritize over 500 proven AI use cases tailored to your industry.
How do we qualify data use to meet AI-expected confidence requirements?
Qualifying the use ensures that the data continuously meets the requirements, whether it is for training, developing or running a model in operations. Use the following parameters to ensure data meets expected confidence requirements for AI use cases:
Validation and verification: Regularly ensure data meets requirements during development and operations.
Performance and cost: Data should meet operational service level agreements, including response time and cost efficiency.
Versioning: Track and manage different data versions to handle model drift and pipeline issues.
Continuous regression testing: Develop test cases to detect failures and data drift.
Observability metrics: Monitor data health, including timely delivery and accuracy.
How do we govern AI-ready data in the context of the use case?
Define the ongoing data governance requirements the data must meet in support of the AI use case using parameters such as:
Data stewardship: Apply policies throughout the data life cycle, including model access and development.
Standards and regulations: Comply with evolving AI regulations, such as the AI EU Act and GDPR.
AI ethics: Address ethical considerations, like the use of real customer data for training.
Controlled inference and derivation: Track how models interact and ensure governance.
Data bias and fairness: Proactively manage data bias and test models with adversarial datasets.
Data sharing: Facilitate data and metadata sharing to support various AI use cases.
More about the key stages on the roadmap to achieving AI-ready data
Based on extensive interactions with clients who have successfully implemented AI-ready data initiatives, Gartner recommends five steps for D&A leaders on the journey to AI readiness.
Assess data management readiness: Evaluate the current state of your data management practices to identify gaps and areas for improvement.
Gain buy-in from the board: Secure executive support and alignment to ensure the necessary resources and commitment for AI initiatives.
Evolve data management practices: Adapt and enhance data management strategies to meet the specific requirements of AI-ready data.
Extend the data ecosystem: Expand your data infrastructure and capabilities to support diverse and scalable AI use cases.
Scale and govern: Implement robust data governance frameworks to ensure data quality, compliance and ethical use as your AI initiatives grow.
Are you a CIO or IT leader at a midsize enterprise?
See how your peers are navigating AI adoption, vendor decisions and evolving business demands — with tools tailored to your role:
Explore our resources for midsize enterprises
Check out a curated list of Gartner’s most popular research being utilized by your peers
AI-ready data FAQs
What is AI-ready data?
AI-ready data means that your data must be representative of the use case, of every pattern, errors, outliers and unexpected emergence that is needed to train or run an AI model for a specific use. It’s a process and a practice based on availability of metadata to align, qualify and govern the data.
How do we make all of our data ready for AI?
There is no way to make data AI-ready in general or in advance. The readiness of data for AI depends on how the data will be used. For example, very different datasets would be required to build a predictive maintenance algorithm versus applying GenAI to enterprise data.
If our data is high quality, does that make it AI-ready?
“High-quality” data — as judged by traditional data quality standards — does not equate to AI-ready data. When thinking about data in the context of analytics, for example, it’s expected to remove the outliers or cleanse the data to support the expectations of the humans. Yet, when training an algorithm, the algorithm will need representative data. This may include poor-quality data, too.
Attend a Conference
Experience Data and Analytics conferences
With exclusive insights from Gartner experts on the latest trends, sessions curated for your role and unmatched peer networking, Gartner conferences help you accelerate your priorities.
8 – 10 Mar 2027
Gartner Data & Analytics Summit
Orlando, FL

Drive stronger performance on your mission-critical priorities.