Accessible, accurate, usable data is essential if you want your D&A function to produce business results.
- Gartner client? Log in for personalized search results.
Data Quality: Best Practices for Accurate Insights

Develop a balanced approach to data quality improvement
Trusted, high-quality data is key to enabling a data-driven enterprise, yet many D&A and AI initiatives fail because of poor data quality. Generative AI will rapidly transform how technical professionals ensure data quality in their data environments. Download this research to learn:
- Use cases
- Data quality capabilities
- Benefits and impacts of large language models on data quality practices
Improve D&A results and decrease costs with high-quality data
Boost the value from your data and analytics program with a foundation of data quality. Follow these practices to set up an effective data quality program.
Data Quality: What and Why?
Scope the Data Quality Program
Measuring Data Quality
Data Quality Tools
What is data quality and why is it important?
Data quality refers to the usability and applicability of data used for an organization’s priority use cases — including AI and machine learning initiatives. Data quality is usually one of the goals of effective data management and data governance. Yet too often organizations treat it like an afterthought.
Why is data quality important to the organization? In part because poor data quality costs organizations at least $12.9 million a year on average, according to Gartner research from 2020.
A number of common challenges hinder organizations and make it difficult for them to address their data quality issues, such as:
- Growing regulatory requirements from government or industry. These include GDPR and CCPA, which restrict how organizations manage personal data and make them accountable for any personal data they hold.
- Inconsistency in data across sources. Named as the most challenging data quality problem, according to Gartner, is the result of having data stored and maintained in silos with significant overlaps, gaps or inconsistencies. If they are not connected, data standardization becomes much harder.
- Lack of resources. Organizations may have a data quality program in one department or in one data domain but cannot scale it due to a scarcity of skills, experience and resources.
- Lack of ownership. While business leaders agree that data quality matters, they do not view it as their responsibility, nor do they necessarily understand how data related to their domain relates to broader enterprise outcomes. Yet data quality is a business discipline. How business users enter data, use data and manage the data are the foundations of data quality. Ownership and collaboration among stakeholders are essential.
{kind=link}

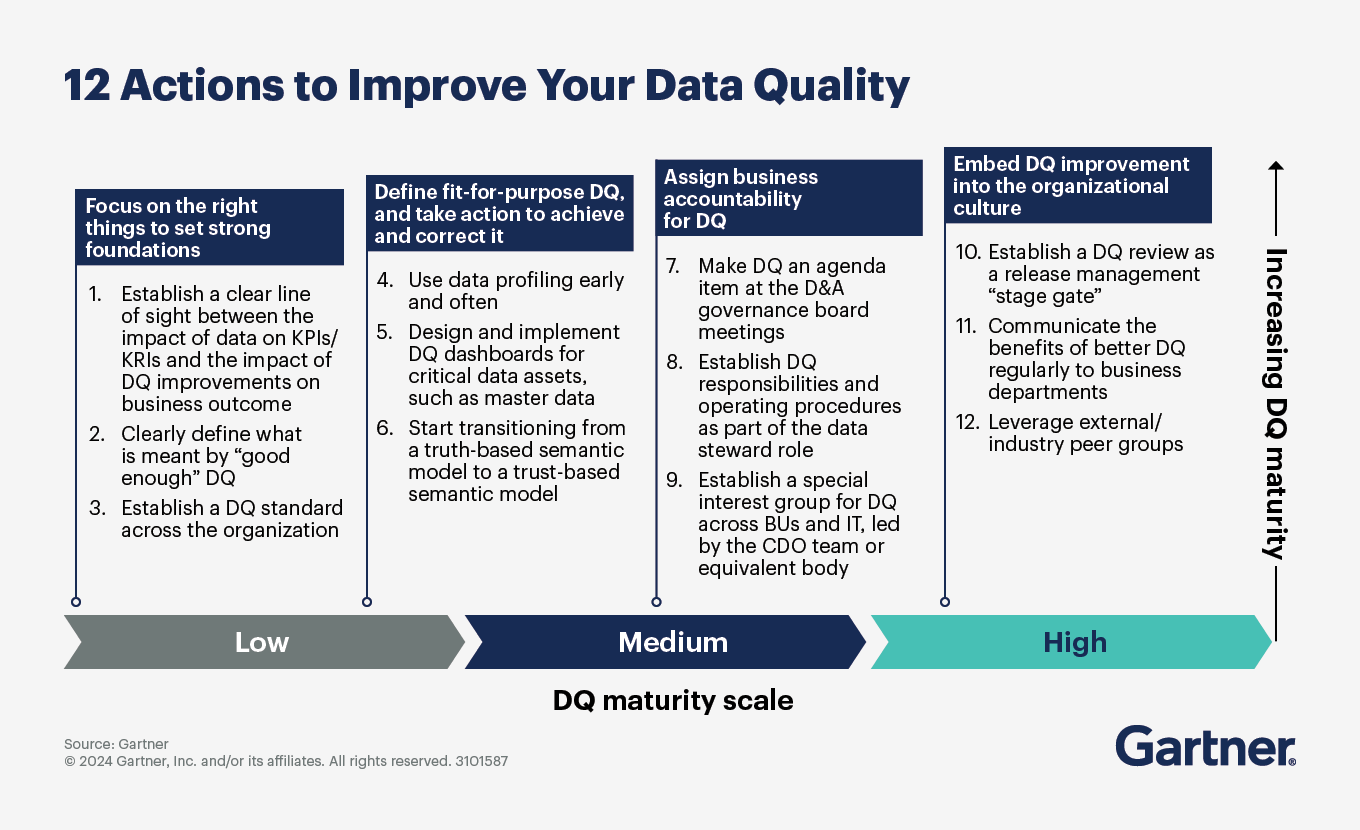
The first two issues are related to data itself. The second two are related to data management. Data and analytics leaders can mitigate these challenges by establishing a modern data quality program that has a defined scope, establishes key processes for data quality measurement and leverages modern data quality technology tools.
Set your data quality priorities based on the most important business use cases
Defining the scope of your data quality program is essential for setting expectations and establishing priorities. Data and analytics leaders cannot and should not aim for data quality everywhere because not all data is equally important. Setting the scope too wide taxes resources without producing business benefits.
Instead, set the scope of your data quality efforts using the following two views into your organization’s data use cases:
Value and risk
Map the organization’s business use cases and data resources along the dimensions of value and risk. Those with the potential to produce high value from high data quality, and face severe risks from low data quality, get priority from the data quality program across a wide scope of activities.
Data expanse
Categorize data sources based on whether the organization’s use cases leverage the data at a centralized, regional or local level.
Centralized data comprises the most critical and commonly shared datasets, such as master data. The scope for this type of data is usually large because its impact on user communities and business processes is vast. Responsibility for, and collaboration on, data quality for centralized data require multiple stakeholders across the organization.
Regional data is also shared, but not as widely as centralized datasets are. The data quality program should have a generous scope for this data. Accountability and collaboration are likely limited to the business unit leaders who leverage the data source.
Local data serves a single purpose and is not shared. The scope of the data quality program is small, and responsibility for it sits with the users of that data.
Organizations just starting with a data quality program can begin anywhere, based on the use-case priorities you have set. Starting with centralized data is often most important, but If your organization lacks experience and you do not yet have full buy-in from the range of stakeholders affected by centralized data, you could start with local datasets.
Data quality dimensions and data quality metrics help drive impact
According to Gartner surveys, 59% of organizations do not measure data quality. That makes it difficult to know what a lack of quality is costing you and how much improvement your data quality management program is producing.
So how do you measure and improve data quality?
By taking steps to understand the dimensions of data quality, choosing the dimensions and corresponding metrics that matter to you, applying data profiling and analyzing the results.
Understand your data quality dimensions
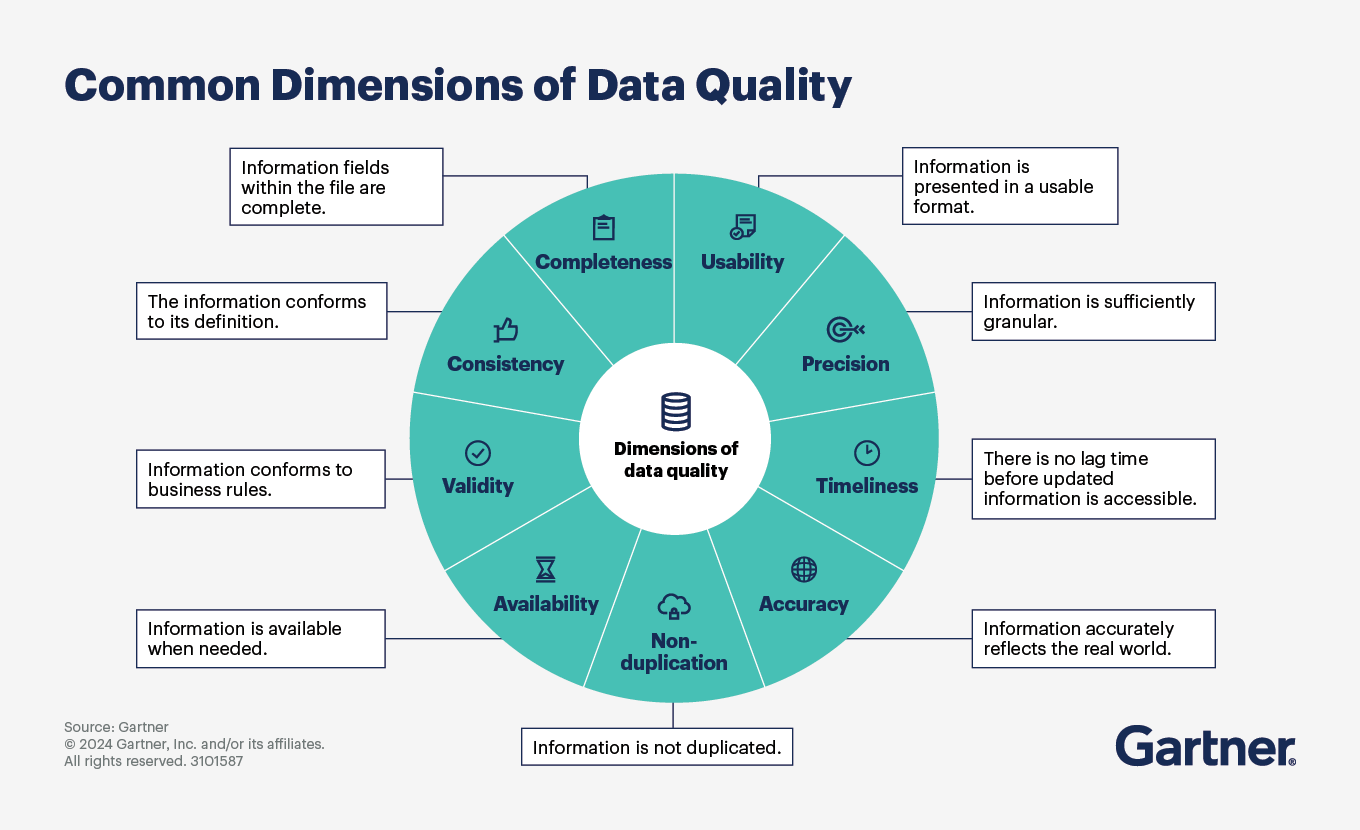
Organizations measure data quality based on the data quality dimensions that matter to them. The nine most common are:
Accessibility. Data is available, easily retrieved and integrated into business processes.
Accuracy. Data value accurately reflects the real-world objects or events that the data is intended to model.
Completeness. Records are not missing fields, and datasets are not missing instances.
Consistency. Data that exists in multiple locations is similarly represented and structured.
Precision. Data is recorded with the precision required by business processes.
Relevancy. Data is applicable to one or more business processes or decisions.
Timeliness. Data is updated with sufficient frequency to meet business requirements.
Uniqueness. Each data record is unique based on how it is identified.
Validity. Data conforms to the defined business rules/requirements and comes from a verifiable source.
Choose data quality metrics that are appropriate and important
Select the data quality dimensions that are useful to your use cases and identify data quality metrics for them. There is no need to apply all of them at once, nor to apply all in the same way to all data assets. After all, not all data is equally important nor used the same way.
Instead, work with stakeholders to define the important data quality metrics and set expectations for the level of quality they need. For centralized and regional data resources, make sure all the affected stakeholders align their definitions and expectations. Set priorities for which metrics are necessary and which are nice to have or optional. Finally, select two or three that are most important for the use case to measure and improve.
{kind=link}

Apply data profiling based on the priority metrics
Data profiling is the process of measuring data quality by reviewing source data and understanding structure, content and interrelationships to identify potential data quality problems.
There are two types of data profiling:
Column-based profiling provides statistical information about data.
Rule-based profiling validates data against business logic or rules.
Data profiling capabilities are available in commercial data quality tools or in open-source data profiling tools. Organizations can also write their own custom-built queries to conduct data profiling on their data sources.
Analyze results
Input the results from your data profiling effort into a heat map that allows you to visualize where data quality problems exist and their relative importance to the business. These insights allow you to identify and investigate data quality problems, estimate potential impacts, build a business case for solving them and identify prevention approaches so the problems don’t recur.
Leverage modern data quality tools to accelerate your processes
The market for data quality technology has evolved in recent years to include an array of solutions that enable organizations to accelerate time to value for their data assets, reduce risk and increase competitive advantage. In particular, augmented data quality solutions represent a fundamental shift in solving data quality issues using active metadata, AI (e.g., NLP) and graph technologies.
Data and analytics leaders should note that data quality tools do not exist alone. Instead, organizations deploy them to support a broader set of data management processes or use cases, like data integration or master data management. Thus when evaluating which solution is right for your needs, data and analytics leaders should weigh the relative importance of each capability to the use cases they hope to support.
Overall, Gartner emphasizes the following 10 critical capabilities organizations should consider when evaluating for data quality solutions:
Profiling
Parsing, standardizing and cleansing
Analytics and interactive visualization
Matching, linking and merging
Multidomain support
Business-driven workflow and issue resolution
Rule management and data validation
Metadata and lineage
Monitoring and detection
Automation and augmentation
Gartner research evaluates augmented data quality solutions based on their applicability to the following use cases:
Data analytics, AI and machine learning
Data engineering (including data integration and data migration)
Data and analytics governance
Master data management
Operational/transactional data
Attend a Conference
Experience Data and Analytics conferences
With exclusive insights from Gartner experts on the latest trends, sessions curated for your role and unmatched peer networking, Gartner conferences help you accelerate your priorities.
8 – 10 Mar 2027
Gartner Data & Analytics Summit
Orlando, FL

FAQ on data quality
What is data quality?
Data quality refers to the usability and applicability of data used for an organization’s priority use cases — including AI and machine learning initiatives. Data quality is usually one of the goals of effective data management and data governance. Yet too often organizations treat it like an afterthought.
How do I measure and improve data quality?
Organizations measure data quality based on the data quality dimensions that matter to them. The nine most common are:
Accessibility
Accuracy
Completeness
Consistency
Precision
Relevancy
Timeliness
Uniqueness
Validity
Why is data quality important to an organization?
Data quality is crucial to an organization because it ensures accurate, reliable and timely information, which supports informed decision making and enhances operational efficiency.
Drive stronger performance on your mission-critical priorities.