Support data access across the business with the flexible and augmented capabilities enabled by a data fabric.
- Gartner client? Log in for personalized search results.
How Data Fabric Can Optimize Data Delivery

Simplify and scale data integration with data fabric’s active metadata-assisted automation
Data and analytics leaders are increasingly challenged to manage their growing data assets in a more distributed environment. Data fabric can help. This presentation provides:
A definition of data fabric, its benefits and what organizations need to adopt it
How it fits into existing data management and data architecture approaches
Step-by-step insight into how to build a composable data fabric design
Faster, better data management with data fabrics
Address the challenge of managing diverse and distributed data sources with a data fabric that leverages metadata to automate and improve data management tasks.
What is Data Fabric?
Metadata
Data Fabric vs. Data Mesh
Data Fabric and Benefits
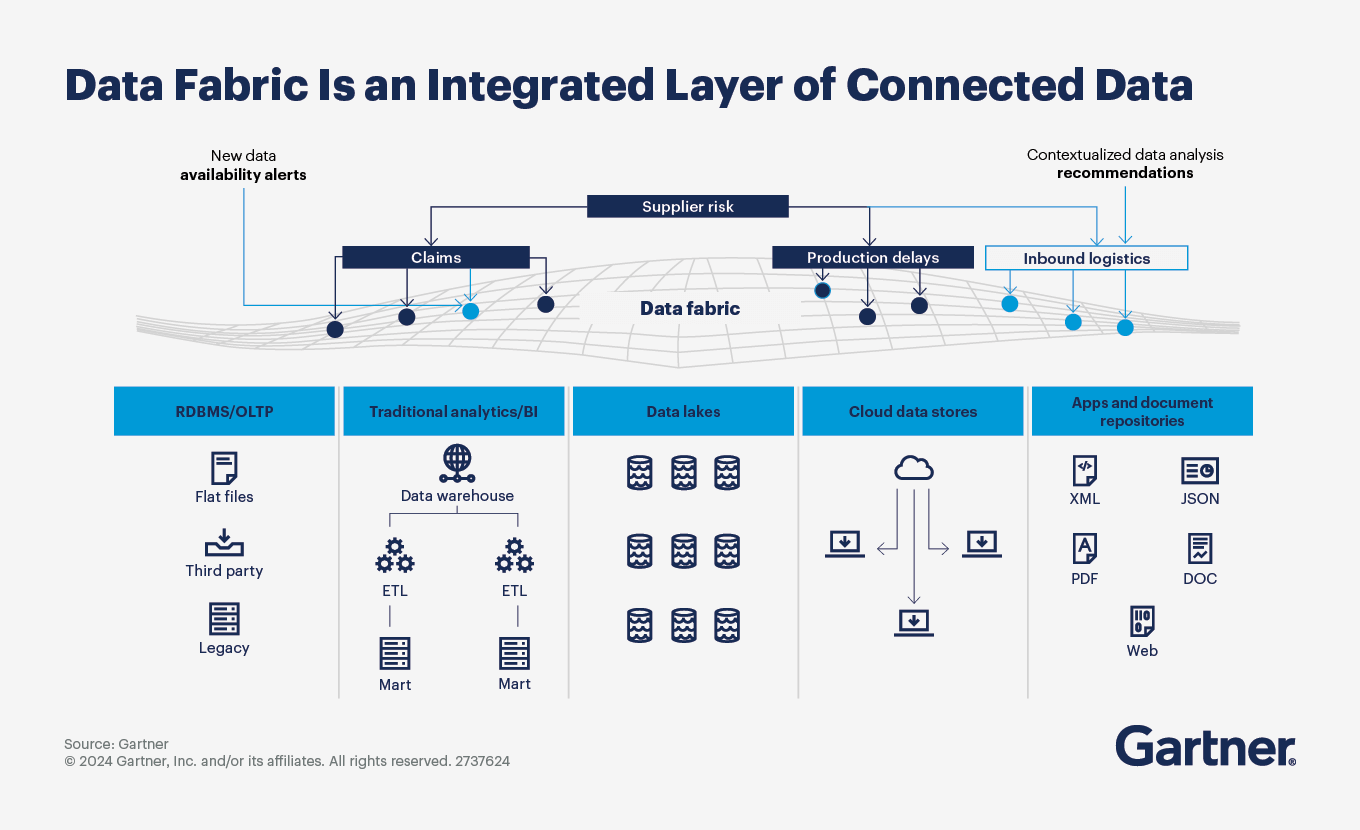
Data fabric is an emerging data management and data integration design concept. Its goal is to support data access across the business through flexible, reusable, augmented and sometimes automated data integration.
Data fabric has emerged as a solution to the common challenge of collecting, connecting, integrating and delivering data from dispersed data sources to the users who need it. In today’s context of increasing data and application silos, coupled with limited data and analytics talent, data fabric promises to simplify the organization’s data integration infrastructure and create a scalable solution that reduces technical debt (also see Modernize Data Management to Increase Value and Reduce Costs).
Data fabric core capabilities
In its simplest form, a data fabric takes in metadata from participating systems and users, analyzes it, and produces alerts and recommendations highlighting how data could be better organized, integrated, given meaning and used to improve the user experience and business outcomes.
The benefits of data fabric
Data fabric appeals to many organizations because it leverages existing metadata as well as infrastructure, such as logical data warehouses. There is no “rip and replace” with a data fabric design. Instead, organizations can leverage data fabrics to augment (or completely automate) data integration design and delivery, while capitalizing on sunk costs in existing data lakes and data warehouses.
{kind=link}
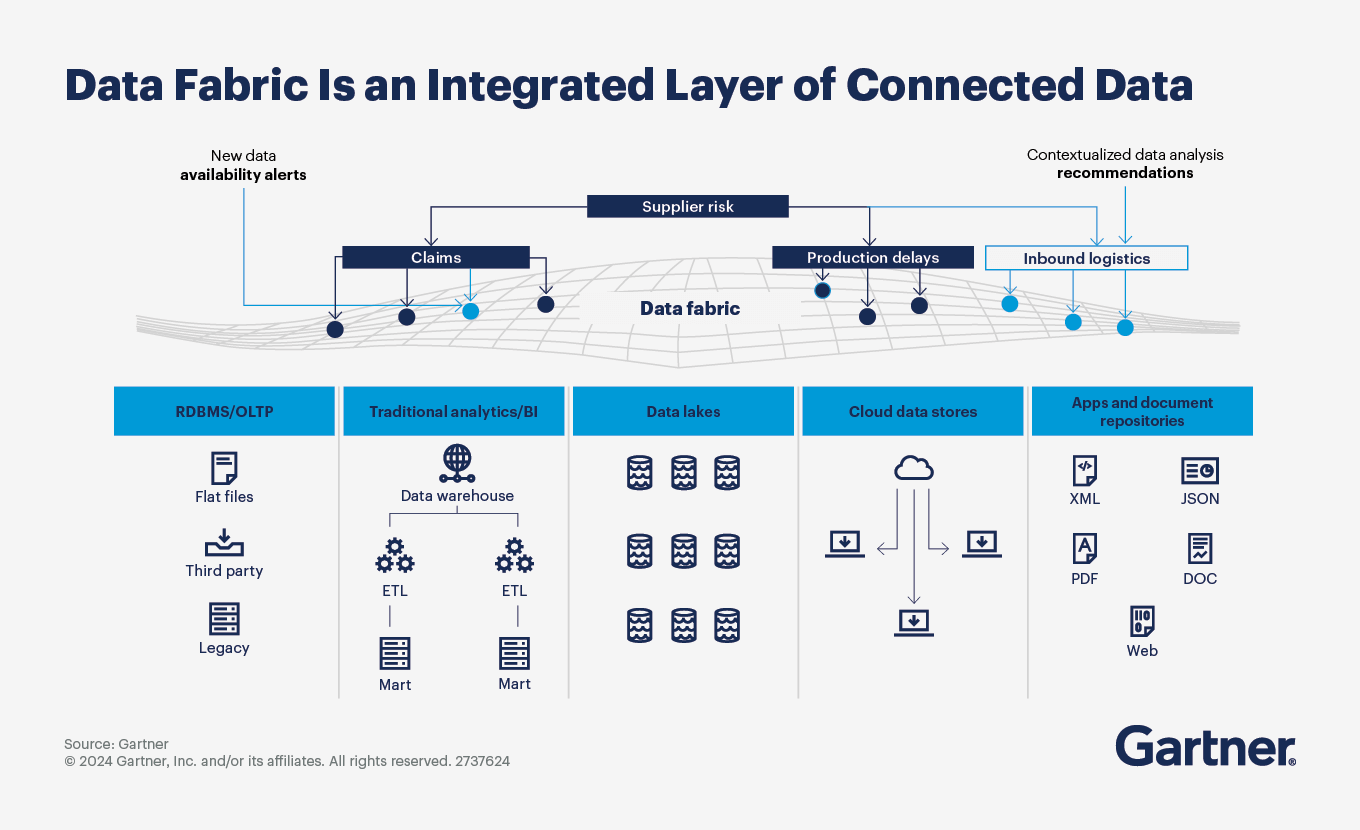
Though data fabric is not a mature technology, and no single vendor currently delivers all data fabric components, its potential benefits apply to different parts of the organization, such as:
Business units — Enables nontechnical business users to quickly find, integrate, analyze and share data
Data management teams — Delivers productivity advantages through automated data access and integration, as well as increased agility, for data engineers, resulting in faster delivery of data requests
Overall organization — Delivers faster time to insight from data and analytics investments, improved utilization of organizational data, and reduced cost through insights on effective data design, delivery and utilization
For an effective data fabric implementation, start with metadata
Data fabric relies on metadata, which is the “data in context” that documents the contextual what, when, where, who and how of the data in the organization. Metadata is produced as a byproduct of data moving through enterprise systems.
There are four types of metadata: technical, operational, business and social. Each of those types can be either “passive” metadata that organizations collect but do not actively analyze, or “active” metadata that identifies actions across two or more systems that use the same data. By definition, a data fabric converts passive into active metadata.
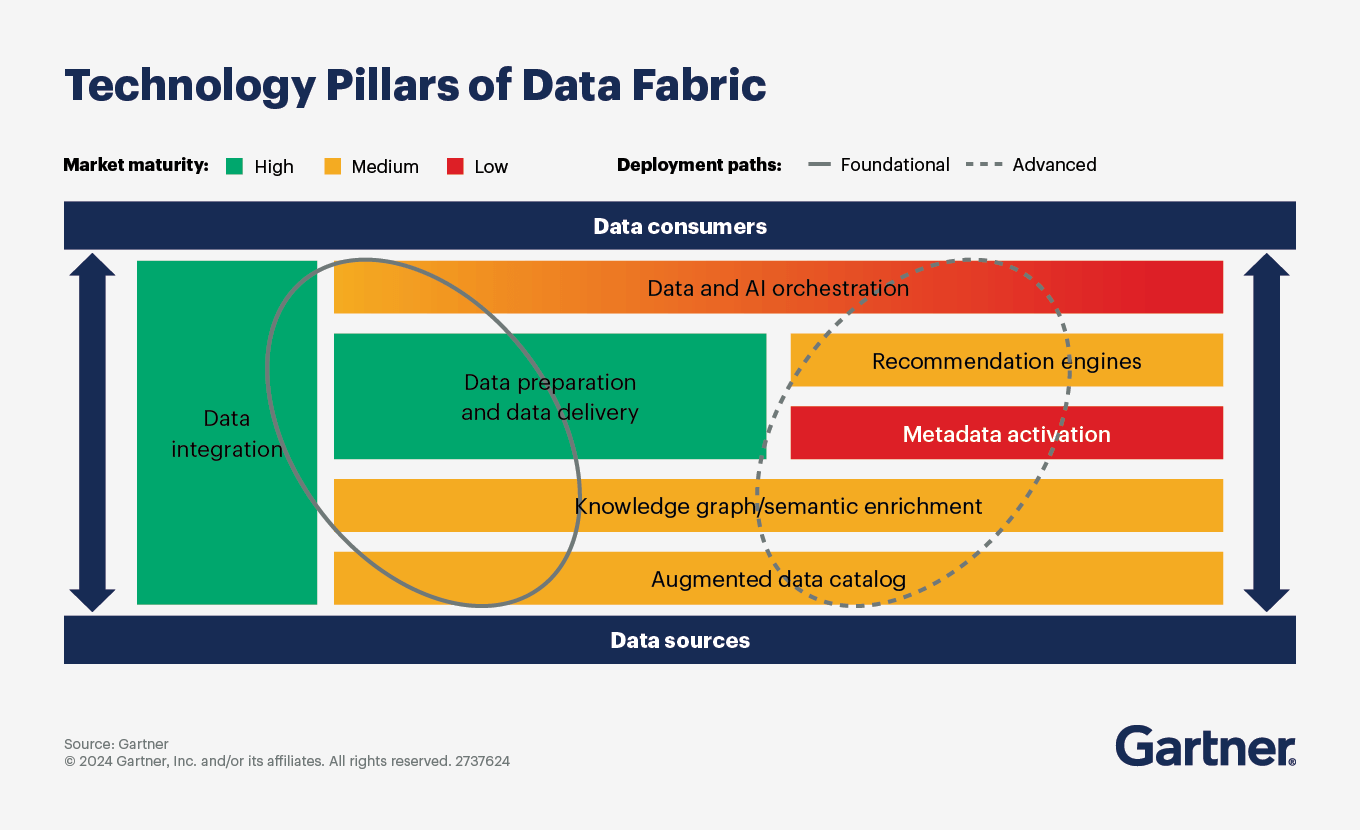
How to build a composable data fabric
The first step is to augment a data catalog. Data fabrics are composable, meaning they are made up of multiple technical components that organizations combine. One of the components is an augmented data catalog. This uses AI/ML to connect to different data sources and find, tag and annotate them. The resulting data catalog curates an inventory of distributed data assets and their associated passive metadata. It also helps stakeholders collaborate on data governance and facilitates communication about any shared semantics related to data from different sources.
The next step is to activate the collected metadata by performing graph analytics on it and using the output to train an AI/ML model to automate data integration and data management tasks. From this foundation, data and analytics teams can produce knowledge graphs that expose connections between your organization’s varied data assets and their users.
Finally, organizations can enrich their knowledge graphs with semantics, or the business meaning and relationships in the data. Semantics on top of knowledge graphs enable better analytics and more informed AI/ML models.
{kind=link}

With these steps complete, the ML engines of the data fabric are able to start informing and automating certain data integration tasks and data management activities. Depending on the sophistication of data fabric, the degree of automation will progress as follows:
Engagement — For example, enable less-skilled integrators to find and integrate data sources or subject matter experts to use semantic search to better understand data.
Insights — For example, enable automated tagging and annotation, dynamic schema recognition, anomaly detection and reporting, highlighting sensitive attributes for GDPR, etc.
Automation — For example, enable automated correction of schema drifts, auto-integrate “next best” data sources, recommend optimal transformations and promote self-service integration to production environments.
Data fabric and data mesh are independent concepts that can coexist
The terms “data fabric” and “data mesh” are often used interchangeably or even discussed as competing approaches. In fact, they are independent concepts. Under the right circumstances, they can be used to complement each other.
To recap, data fabric is an emerging data management design that uses metadata to automate data management tasks and eliminate manual data integration tasks. Data mesh, in contrast, is an architectural approach with the goal of building business-focused data products in environments with distributed data management and data governance responsibilities.
Though data fabrics are about data management and data mesh is about data architecture, both share the same goal of enabling easier access to and use of data.
Some key distinctions and complements are:
Technology — A data fabric can work with different integration styles in combination to enable a metadata-driven implementation and design. A data mesh is a solution architecture that can guide design within a technology-agnostic framework.
Purpose — A data fabric discovers data optimization opportunities through the continuous use and reuse of metadata. A data mesh takes advantage of business subject matter expertise to develop context-based data product designs.
Data authority and data governance — A data fabric recognizes and tracks data use cases that can be authoritative, and it treats all subsequent reuse by adding to, refining and resolving data authority differently by use case. A data mesh emphasizes the originating data sources and use cases to produce combinatorial data products for specific business contexts.
- People — A data fabric encourages augmented data management and cross-platform orchestration to minimize human efforts. A data mesh, at present, promotes the ongoing manual design and orchestration of existing systems with human intervention during maintenance.
Considering the costs of data fabric vs. data mesh
Data and analytics leaders will eventually need to consider the costs of modernizing through data fabric and/or data mesh. The total cost to deliver either may be similar relative to design and deployment. The augmented data management capabilities included in a data fabric, however, improve the cost model for ongoing improvement, maintenance and data governance.
Moreover, the data fabric relies heavily on existing technology tools and platforms. A mesh, in contrast, shifts the focus of cost toward delivering data services. In the cloud era, data costs and subscription flexibility should be considered, as should current usage patterns and any directional changes in their budget and allocation behavior.
Attend a Conference
Experience Data and Analytics conferences
With exclusive insights from Gartner experts on the latest trends, sessions curated for your role and unmatched peer networking, Gartner conferences help you accelerate your priorities.
8 – 10 Mar 2027
Gartner Data & Analytics Summit
Orlando, FL

Drive stronger performance on your mission-critical priorities.