Resilience — not panic or repatriation — should guide your next move after cloud disruptions.
- Gartner client? Log in for personalized search results.
{kind=link}
Cloud outages are a wake-up call, but not a reason to abandon ship
Recently, AWS and Azure experienced outages that caused degraded performance and downtime for many organizations. These events highlight an important truth: cloud disruptions happen, but they are not evidence that the cloud is inherently unreliable.
In fact, these incidents follow a familiar pattern seen across all hyperscale cloud providers over the last decade: a regional event, typically resolved within hours, often tied to a network dependency, but not affecting running compute instances themselves.
Moving workloads out of these hyperscale providers (repatriation) or to smaller sovereign clouds (geopatriation) won’t eliminate outage risk. In fact, these moves often introduce new risks and may even slow down your recovery when things do go wrong.
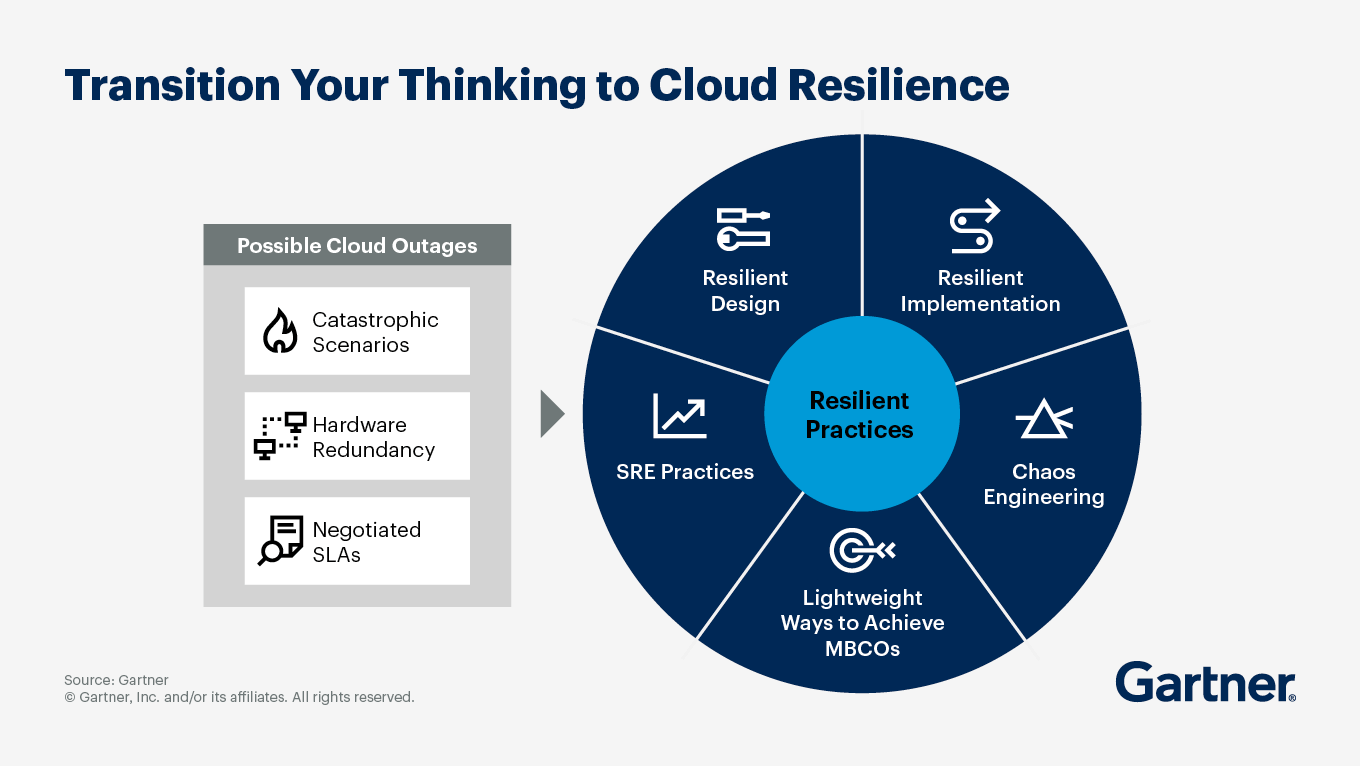
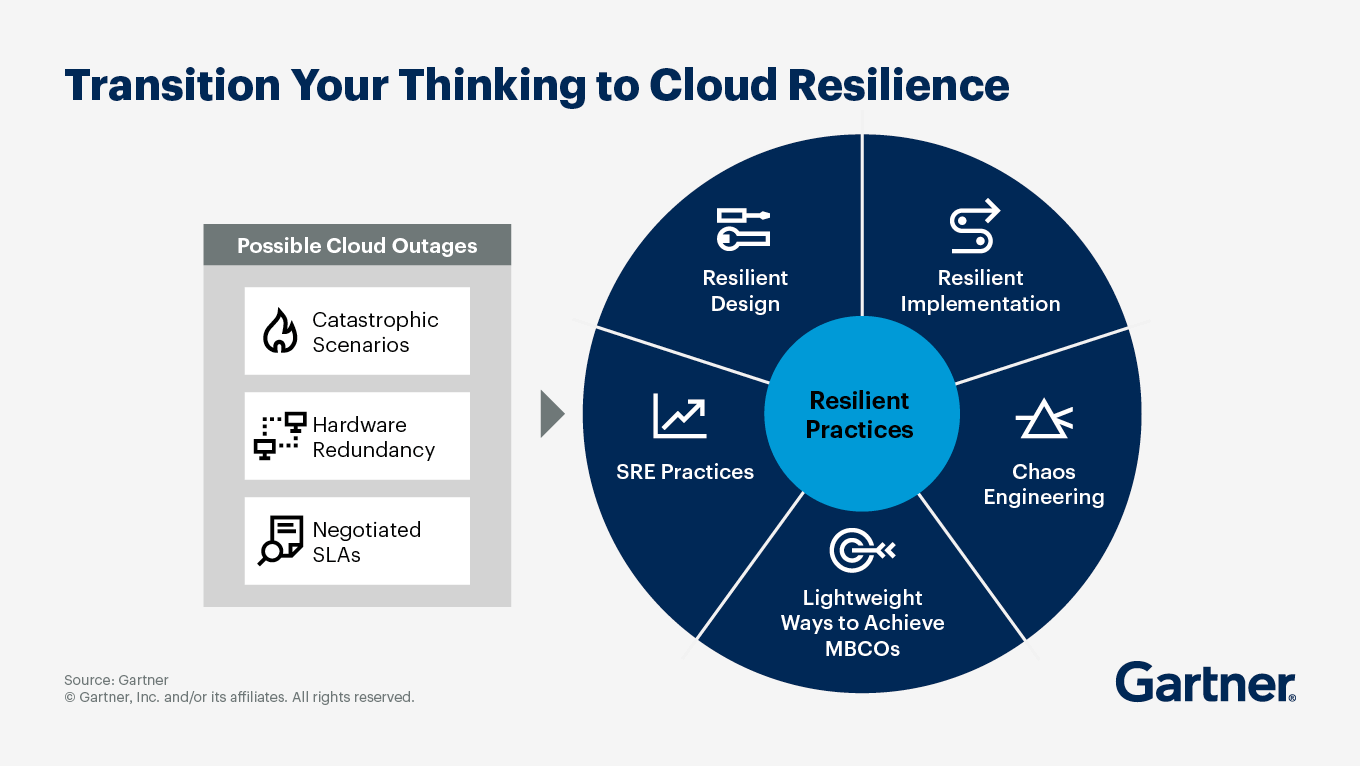
Resist knee-jerk reactions. Building true resilience requires architectural discipline
No cloud provider can promise zero downtime. What sets IT leaders apart isn’t whether they avoid incidents altogether; it’s how they prepare and respond.
Design for failure (because it will happen)
Modern cloud-native apps should distribute workloads across multiple availability zones and be ready to fail over quickly to another region when needed. It’s not about eliminating risk; it’s about reducing blast radius and recovery time. That means understanding service dependencies (like databases or DNS), maintaining up-to-date runbooks and practicing failover drills before disaster strikes.
Legacy apps need extra attention
If you’re still running critical legacy workloads in the cloud, don’t assume resilience comes “out of the box.” Make sure backups are available in secondary regions and that you can actually restore them under pressure. Test disaster recovery regularly so your team knows exactly what to do if their primary region goes dark.
Transparency builds trust
AWS, for example, has been open about its global dependencies and has worked since its December 2021 outage to reduce single points of failure. The October 2025 incident was completely confined to US-East-1, showing progress in fault isolation. This transparency gives CIOs actionable data for risk management instead of leaving them guessing.
Avoid multicloud complexity unless your regulators demand it
It’s tempting to think multicloud is the answer. But Gartner research shows that pursuing multicloud resilience can cost more than it saves, introducing technical complexity without truly eliminating systemic risk.
Maximize single-cloud resilience first
For most organizations — even those facing strict regulations like the Digital Operations Resilience Act (DORA) — investing in robust architectures within one cloud delivers better uptime and simpler operations than trying to juggle multiple providers with different APIs and processes.
Focus on business continuity through substitutability
If your business absolutely cannot tolerate downtime for certain functions, consider application substitutability — having alternative platforms or manual workarounds ready to go if your primary system fails. This pragmatic approach often satisfies both business needs and regulatory scrutiny without ballooning IT budgets.
Don’t let headlines drive strategy. Let data do the talking
Cloud outages make headlines because they affect so many people at once, but context matters. Every major provider has experienced similar events, from Microsoft Azure to Google Cloud Platform. The real differentiator is how well your organization plans for and recovers from inevitable disruption.
The bottom line is clear: Public cloud remains the best option for scalable infrastructure if you invest in resilience upfront — or correct existing deployments if necessary. Don’t let fear steer you toward costly or ineffective alternatives; instead, double down on architecture, process discipline and transparent partnerships with your providers.
Gartner clients can read more in AWS October 2025 Outage Isn’t a Cause for Panic.
Attend a Conference
Join Gartner experts and your peers to accelerate growth
Gather alongside I&O leaders in Las Vegas to gain insight on emerging trends, receive one-on-one guidance from Gartner experts and create a strategy to tackle your priorities head-on.
8 – 10 Dec 2026
Gartner IT Infrastructure, Operations & Cloud Strategies Conference
Las Vegas, NV

Drive stronger performance on your mission-critical priorities.