Deemphasize models and codes in favor of a data-first approach to AI readiness.
- Gartner client? Log in for personalized search results.

{kind=link}
What is data-centric AI, and how do D&A architects prepare for it?
AI increasingly relies on unstructured data inputs like text, images and video, rather than solely on structured data formats. This shift, driven by generative AI (GenAI) technologies, underscores the growing complexity of AI demands. Traditional data management tools must evolve to address these new challenges.
A data-centric approach is key to tackling this complexity. Unlike the traditional methods in AI that prioritize refining algorithms or enhancing code, a data-centric approach focuses on iteratively improving data to optimize AI systems. Here the model and code remain static while the data is continuously improved.
To address the complex demands of unstructured data, modern solutions also incorporate AI augmentations, such as code generation assistants and low-code/no-code capabilities. These innovations streamline data preparation processes and empower organizations to fuel advanced AI systems effectively. By adopting a data-centric mindset and focusing on four key pillars, data and analytics (D&A) architects can position their organizations for success in the era of unstructured AI data.
Gartner for Technical Professionals (GTP) is a specialized service that provides in-depth technical research and insights tailored to the needs of IT professionals and architects who are tasked with implementing technical domain strategies. Talk to Gartner to learn more.
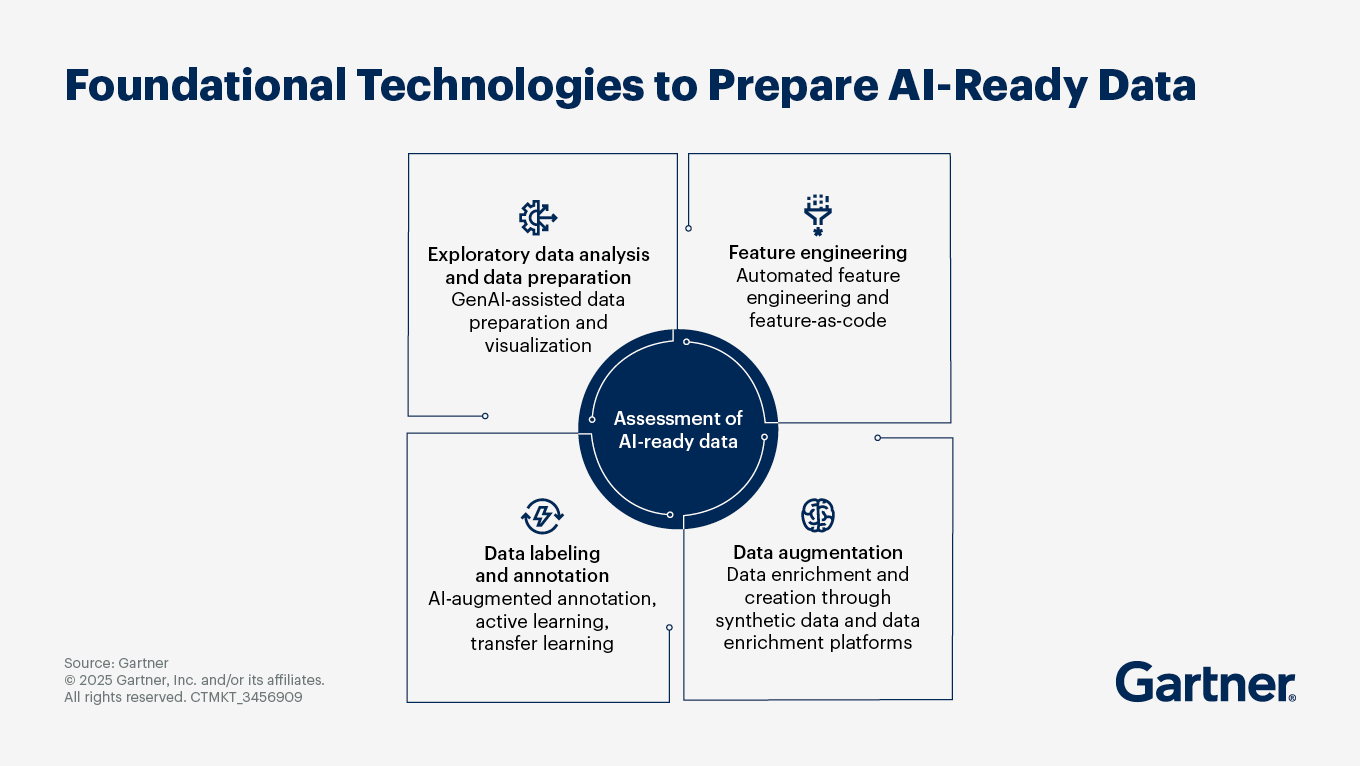
Use four foundational technologies to prepare AI-ready data
For every AI initiative, align the business case with the AI use case. Multiple techniques may apply, each with unique data requirements. Below are four foundational pillars for a data-centric approach.
Exploratory data analysis and data preparation
Data preparation includes exploratory data analysis (EDA), cleansing and transformation to build high-quality datasets for feature extraction and engineering.
Steps to prepare AI-ready data:
Conduct EDA to assess data shape, quality (e.g., duplicates, missing values) and features.
Data preprocessing for traditional AI includes cleaning, shaping, handling missing values and adding quality to data before feature extraction.
Preprocess data for GenAI, following workflows like retrieval-augmented generation (RAG), which involve cleaning, chunking, summarizing, generating embeddings and connecting to output destinations.
Modern AI-augmented tools can:
Automate pipeline generation by inferring transformations
Learn from user interactions to enhance accuracy and efficiency
Lower technical barriers, enabling less experienced users to perform complex data transformations
Feature engineering
Feature engineering involves creating features that add meaning to datasets, improving model performance and accuracy. This process is iterative and resource-intensive but essential for AI readiness.
Steps to engineer features:
Feature creation involves using available data to create features through splitting, binning and one-hot encoding.
Feature transformation focuses on missing features that are replaced if not required by creating a Cartesian product of features and building domain-specific features.
Feature extraction uses dimensionality reduction techniques to reduce the amount of data to be processed, reducing the need for more compute resources.
Feature selection entails selecting a curated subset of features to aggregate the most relevant features for model training.
Automated feature engineering (AFE) uses AI techniques (e.g., feature learning) to automatically generate features using a use-case-agnostic framework.
Data labeling and annotation
Data labeling involves adding metadata to unstructured data to add meaning and context for AI development. Manual labeling, the most time-consuming option, requires exceptional precision, domain and technical expertise, and expense. It is also prone to elevated risk: Outsourcing introduces the possibility that internal private data will be exposed, and human error is inevitable.
Automated data labeling and annotation accelerates the pace, improves the quality and lowers the cost of labeling.
Active learning uses supervised learning to create high-quality proxy informative labels and continues labeling unlabeled data through an interactive process.
Transfer learning uses a pretrained model that has been trained on similar data to label related unlabeled data.
Programmatic labeling uses labeling functions to capture knowledge as code to label data.
Visual prompting uses pretrained vision models to segment areas within an image for labeling.
Data augmentation
Data augmentation is used to flesh out data that lacks the right attributes or is unavailable due to privacy protections. Real-life data that has too little variety or volume for AI training may also benefit from augmentation.
Synthetic data, a form of GenAI, retains the statistical and behavioral aspects of real datasets. It may be generated through statistical sampling from real data, semantic approaches, generative adversarial networks (GAMs) or large language models (LLMs). Used in simulations and computer modeling, synthetic data is key to AI development. It is projected to surpass real data in AI models by 2030.
Data enrichment involves using externally sourced, domain-specific data to augment internal data to satisfy AI use cases requiring highly curated datasets. Data enrichment tools can gather, organize, clean and aggregate third-party data (e.g., from the internet) from disparate sources.
Consider the following when evaluating solutions:
Synthetic data may lack the level of detail required to mimic real-world data.
Data augmentation is an emerging technology with low enterprise adoption rates. In the absence of ready-made solutions, generating synthetic data is expensive and requires highly skilled data scientists with deep-learning expertise.
Are you a CIO or IT leader at a midsize enterprise?
See how your peers are navigating AI adoption, vendor decisions and evolving business demands — with tools tailored to your role:
Explore our resources for midsize enterprises
Check out a curated list of Gartner’s most popular research being utilized by your peers
Data-Centric Approach to AI FAQs
What are some challenges of GenAI?
Traditional data preparation and extract, transform and load/extract, load and transform-style tools have specialized in ingesting and transforming structured data only. Support has been limited for nonrelational data like PDFs, HTML and text files, and audio and video images. To use LLMs, it is important to use emerging techniques with unstructured documents to structure documents into a machine-readable format, performing text extraction, cleaning and chunking, and generating embeddings.
What techniques are used in exploratory data analysis (EDA)?
Univariate nongraphical: calculation of summary statistics with a single variable
Multivariate nongraphical: calculation of summary statistics with multiple variables
Univariate graphical methods: charts with a single variable
Multivariate graphical methods: charts with multiple variables
Are there any special considerations for unstructured data processing?
Ensure that the platform can:
Support the full range of input and output connectors to data sources (e.g., Microsoft SharePoint, Atlassian Confluence), object stores and vector databases (e.g., Pinecone, Weaviate)
Work with the full range of file types and document layouts including PDFs and images, as well as HTML, DOCX, XML and others
Redact personally identifiable information and protected health information from documents to ensure that privacy concerns are addressed
Attend a Conference
Experience Data and Analytics conferences
With exclusive insights from Gartner experts on the latest trends, sessions curated for your role and unmatched peer networking, Gartner conferences help you accelerate your priorities.
8 – 10 Mar 2027
Gartner Data & Analytics Summit
Orlando, FL

Drive stronger performance on your mission-critical priorities.