For the latest, visit Trending Questions on AI and Emerging Technologies. Here, find past questions and answers on emerging technologies.
- Gartner client? Log in for personalized search results.
Archive: Emerging Tech Watch
October 2025
How will AI and robots transform or replace existing jobs?
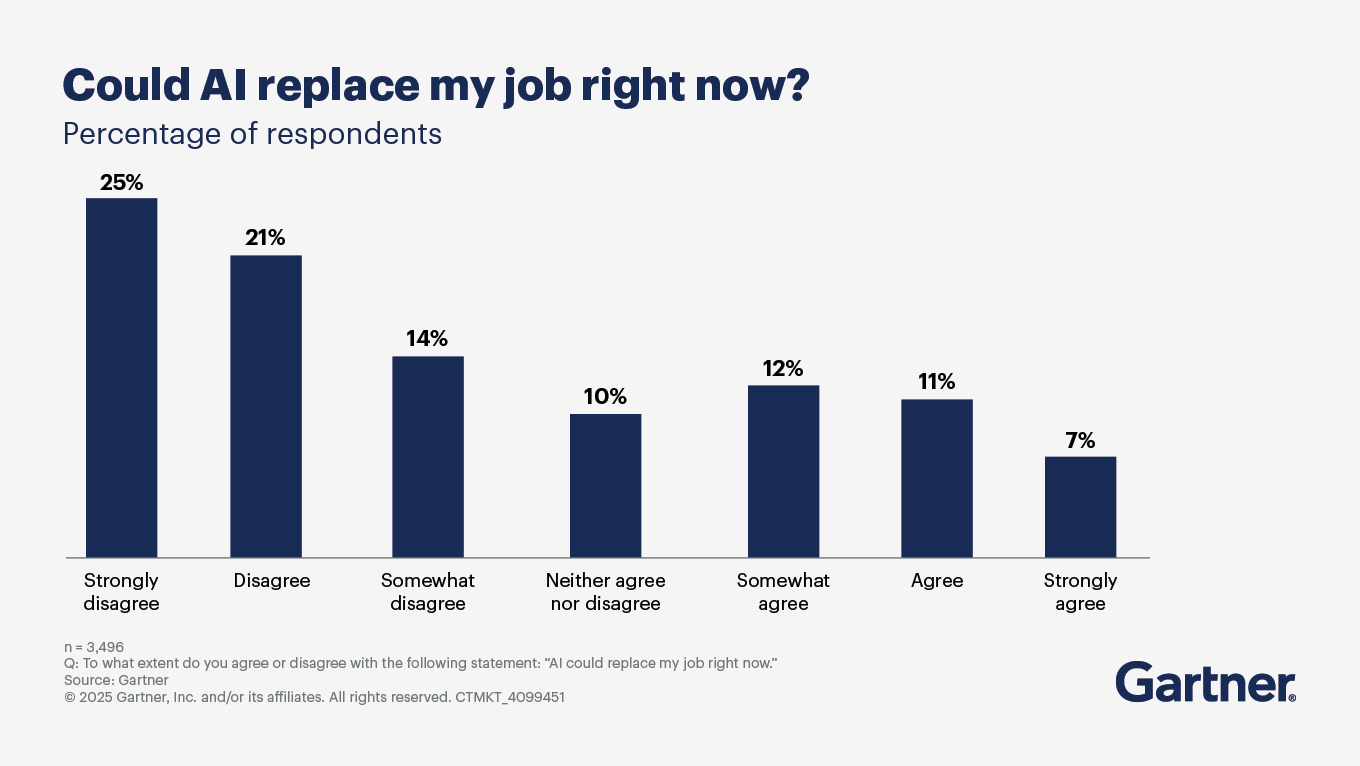
In short, significantly. Gartner predicts that by 2030, 90% of humans will engage with smart robots on a daily basis, due to smart robot advancements in intelligence, social interactions and human augmentation capabilities, up from less than 10% today.
This transformation is characterized by several key trends:
Automation of routine tasks to allow human workers to focus on more complex and value-added activities.
Creation of new roles, like AI engineers, data scientists and AI ethicists. This indicates a transformation in job functions rather than outright job loss.
Enhanced decision-making, such as in customer service, for example, where AI can assist agents by providing real-time data and insights, thereby improving the quality of service.
Workforce augmentation, in part thanks to the rise of polyfunctional robots, which can perform multiple tasks and adapt to various environments. This shift not only transforms job roles but also enhances workplace safety and productivity.
Continuous operation through hot inspection and in-situ monitoring by smart robots, even in hazardous environments.
Physical agency of AI in agent networks, where robots act as the physical embodiment of AI agents — enabling digital intelligence to perceive, interact and act within the real world.
To prepare the workforce for new responsibilities, focus on reskilling, upskilling and carefully managing workforce transitions to mitigate fears and retain talent.
What is spatial computing, and what are its potential use cases?
By Tuong Nguyen
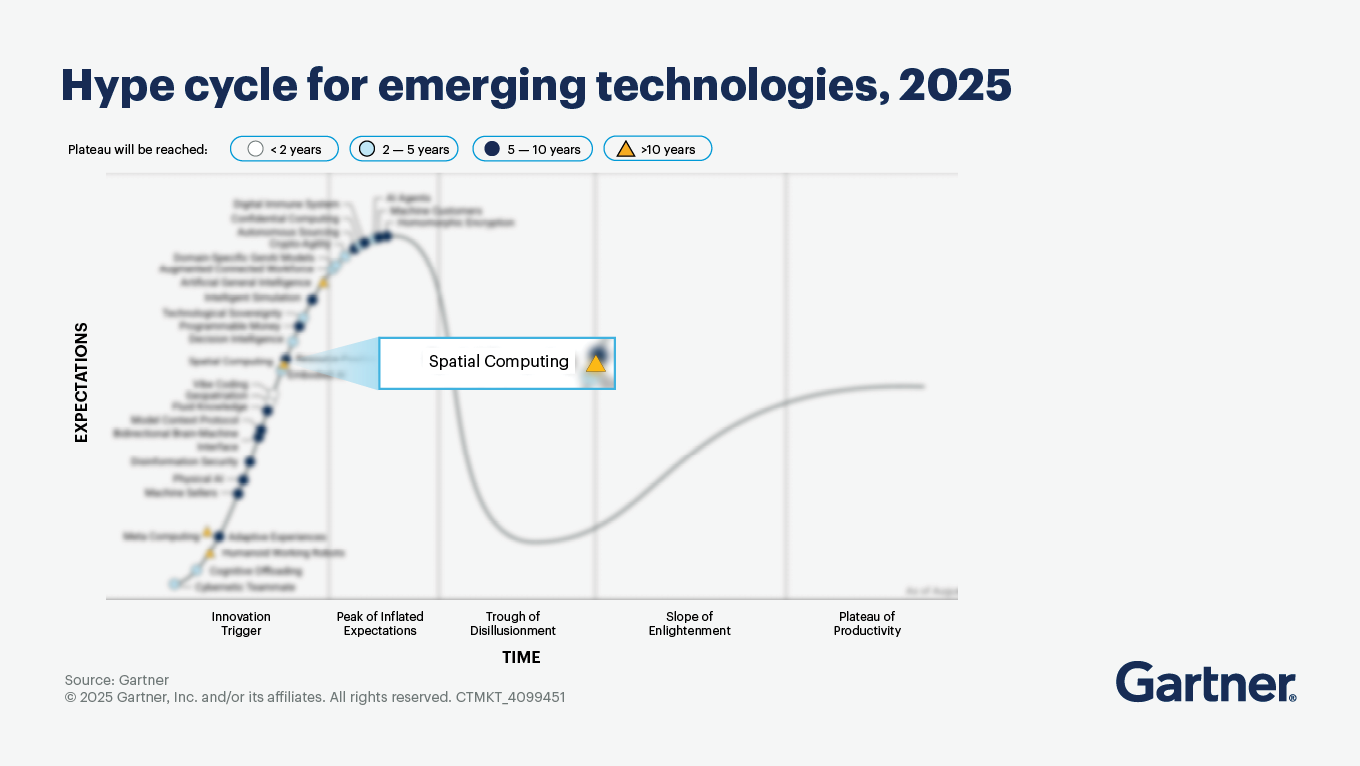
Spatial computing boosts human perception and thinking and improves machines’ ability to understand, move through and interact with real-world locations and objects. By organizing and linking digital content to the real world, this technology unlocks new avenues for business and dramatically improves the effectiveness of interactions between people, systems and their environments.
The market for spatial computing is expected to reach $1.7 trillion by 2033. Potential use cases include the following.
Embodied AI/physical AI uses a shared content source describing the state of and relationships between things to orchestrate and respond. For example, autonomous vehicles respond to first responder vehicles to request green lights, reroute cars and alert pedestrians through connected devices.
Agentic AI is a unifying framework to connect diverse devices and content across public and private data sources using an appropriate graph. For example, enabling AI agents controlling thermostats and those controlling energy-storage battery systems to work together to maximize comfort while saving money and cutting emissions across a neighborhood.
Spatial web is a physical world wide web that delivers just-in-time information and hyperpersonalized experiences and services via an internet of spaces and places for a variety of use cases, including retail, advertising, industrial maintenance and prototyping as well as orchestration and collaboration between AI agents.
As organizations explore these use cases, they must also address challenges such as data privacy, standardization and the integration of spatial computing into existing workflows.
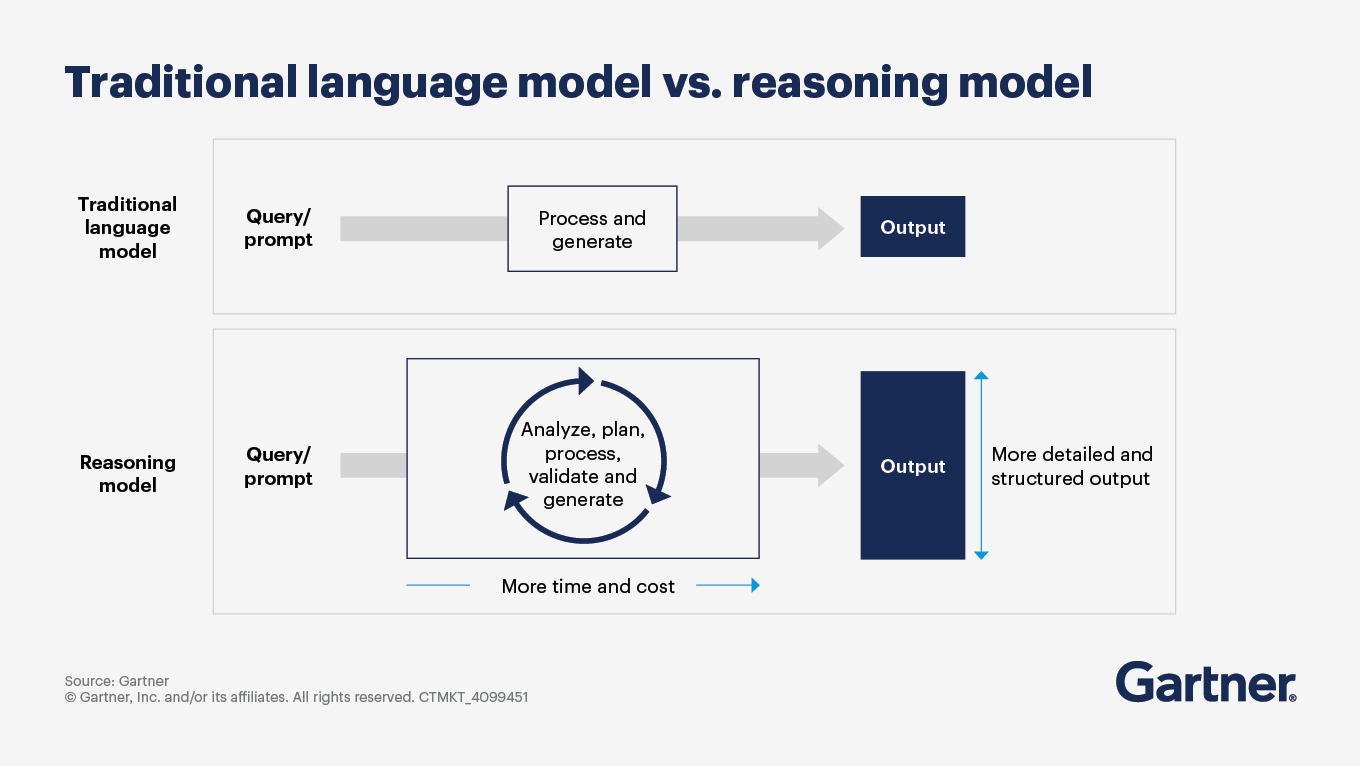
How will reasoning models evolve and transform AI adoption?
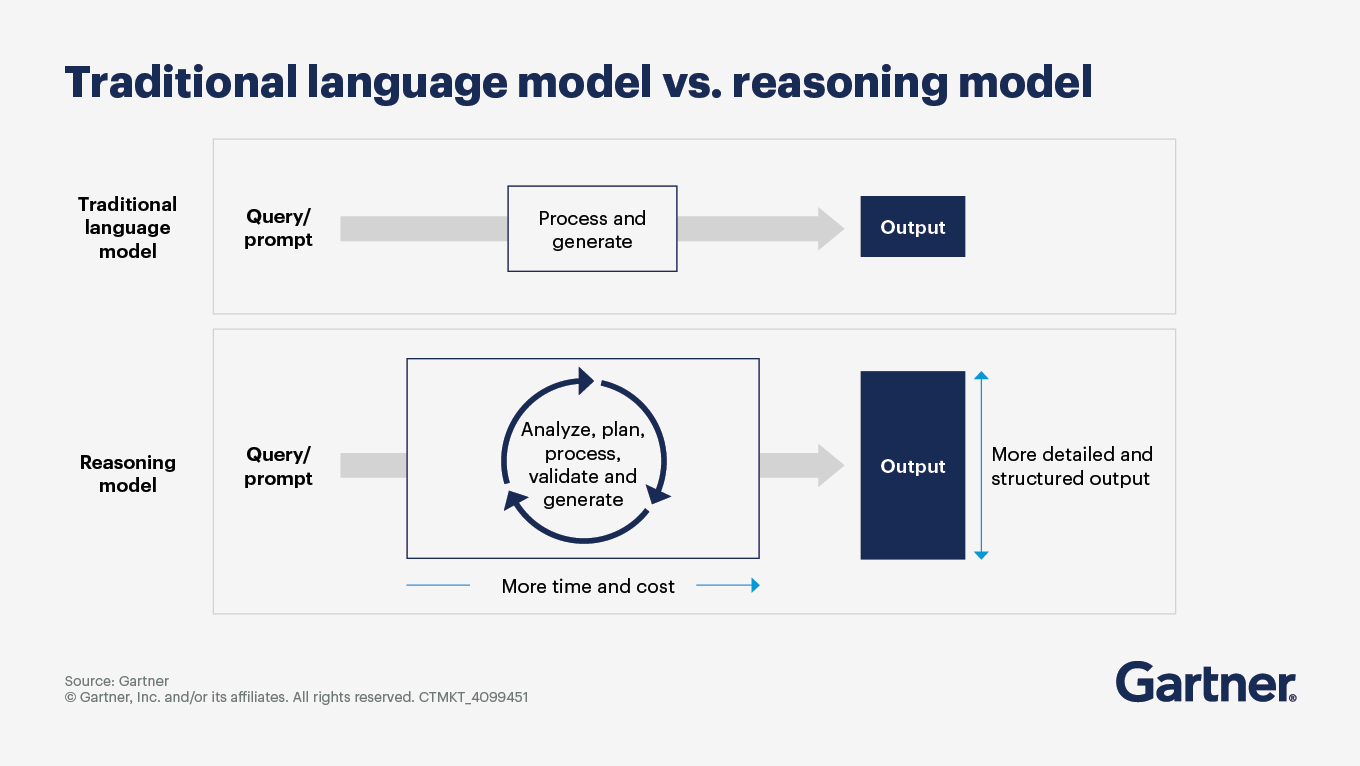
Reasoning models are expected to undergo significant evolution in logical inference, complex problem solving and multistep reasoning. These models will increasingly use chain-of-thought processes and self-reflection, allowing them to mimic human-like thought patterns more effectively than traditional models, which primarily rely on pattern recognition. This evolution is driven by advancements in reinforcement learning, where models are trained to validate their outputs in areas such as math, logic and coding.
Gartner projects that by 2029, investment in reasoning models will underpin the success of more than 70% of agentic AI applications, a significant increase from 0% in 2024.
The shift toward more sophisticated, domain-specific reasoning models will enable organizations to automate complex tasks, improve decision-making and redefine workforce dynamics, ultimately leading to a more integrated and efficient use of AI technologies in business operations. The anticipated growth in agentic AI applications underscores the importance of investing in these advanced reasoning capabilities to stay competitive in an increasingly AI-driven landscape.
September 2025
How should I respond to the launch of Anthropic’s Claude Sonnet 4.5 AI model?
Claude Sonnet 4.5 signals Anthropic’s intention to shift toward domain specialization in an increasingly competitive generative AI (GenAI) model market landscape. Gartner recommends:
- AI leaders: Prioritize using existing, robust infrastructure — such as mature Model Context Protocol (MCP) integrations and established cloud agents — for general office automation. At the same time, selectively pilot Claude Sonnet 4.5 to assess its effectiveness in enabling specialized domain agents, specifically to validate its capabilities for long-running execution and advanced computer use in targeted applications.
- Cybersecurity leaders: Assess Claude Sonnet 4.5 for cybersecurity use cases, but be skeptical about Anthropic’s cybersecurity partners’ improvement claims until independent, competitive validation is available.
- Software engineering leaders: Restrict the use of Claude Sonnet 4.5 to coding use cases that cheaper models cannot achieve, and avoid adopting it as the team’s default “daily driver” due to the high input/output costs.
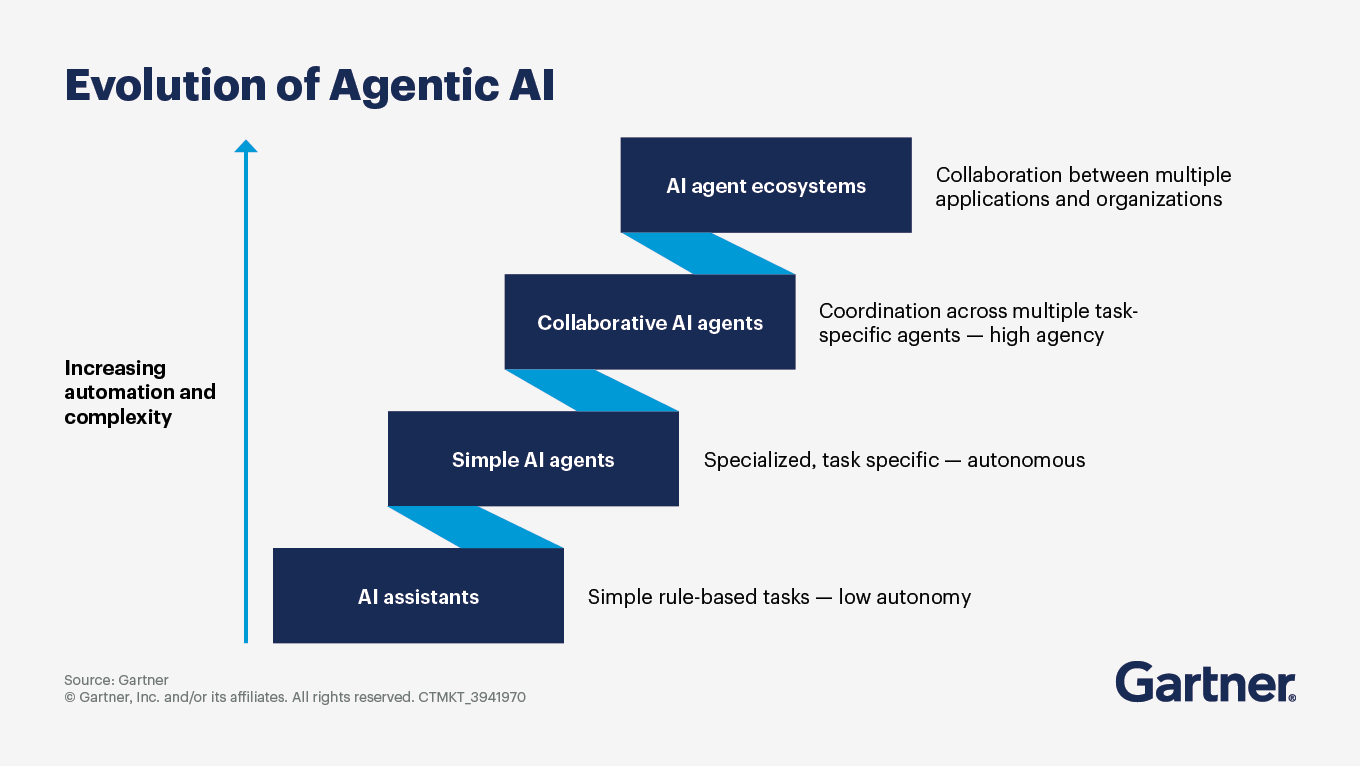
What does the road ahead look like for agentic AI?
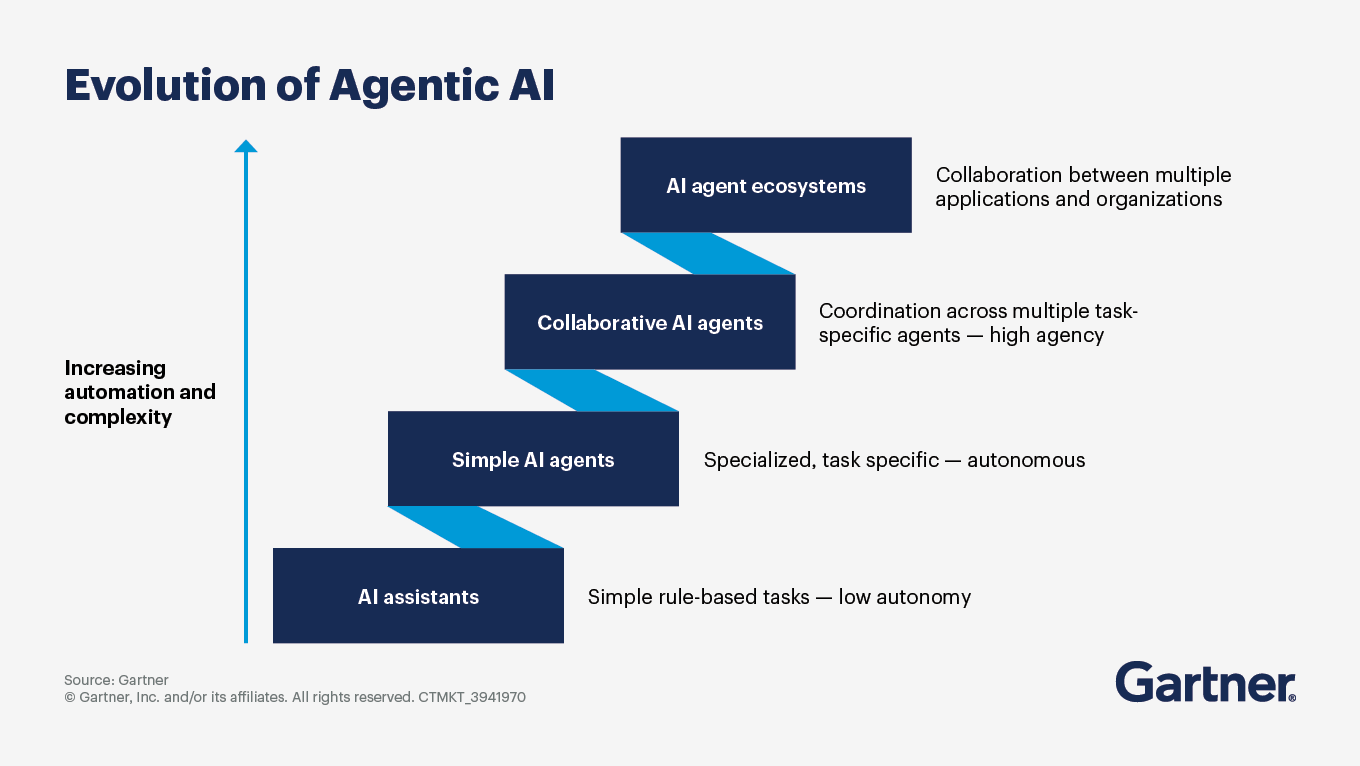
Agentic AI technologies are poised for significant transformation and growth, driven by advancements in AI capabilities, increasing demand for automation and the need for enhanced decision-making processes across various industries. As agentic AI matures, you can expect:
Increased agency and autonomy: This will enhance productivity and efficiency, allowing organizations to automate intricate workflows and processes that were previously labor-intensive.
Integration into business processes: By 2028, it is anticipated that 33% of enterprise software applications will include agentic AI, up from less than 1% in 2024. This will facilitate more sophisticated interactions between humans and AI systems, improving overall operational efficiency.
Focus on use cases with clear value: Gartner predicts that over 40% of agentic AI projects will be canceled by 2027 due to escalating costs or unclear business value. Prioritize agentic AI projects that demonstrate clear business value and ROI.
Challenges in adoption: These include complexity in implementation, the need for robust governance frameworks and ensuring data quality.
Collaboration and governance: Organizations will need to establish clear guidelines for the autonomy granted to AI agents that balance the benefits of automation with the need for oversight.
Market dynamics and competition: The market for agentic AI is expected to grow rapidly, with both startups and established companies investing heavily in this area. Yet, the market is currently rife with “agent washing” with many vendors branding as agentic, regardless of the underlying capabilities. True AI system autonomy — acting as reliable, communicative and collaborative multi-AI-agent systems — remains aspirational..
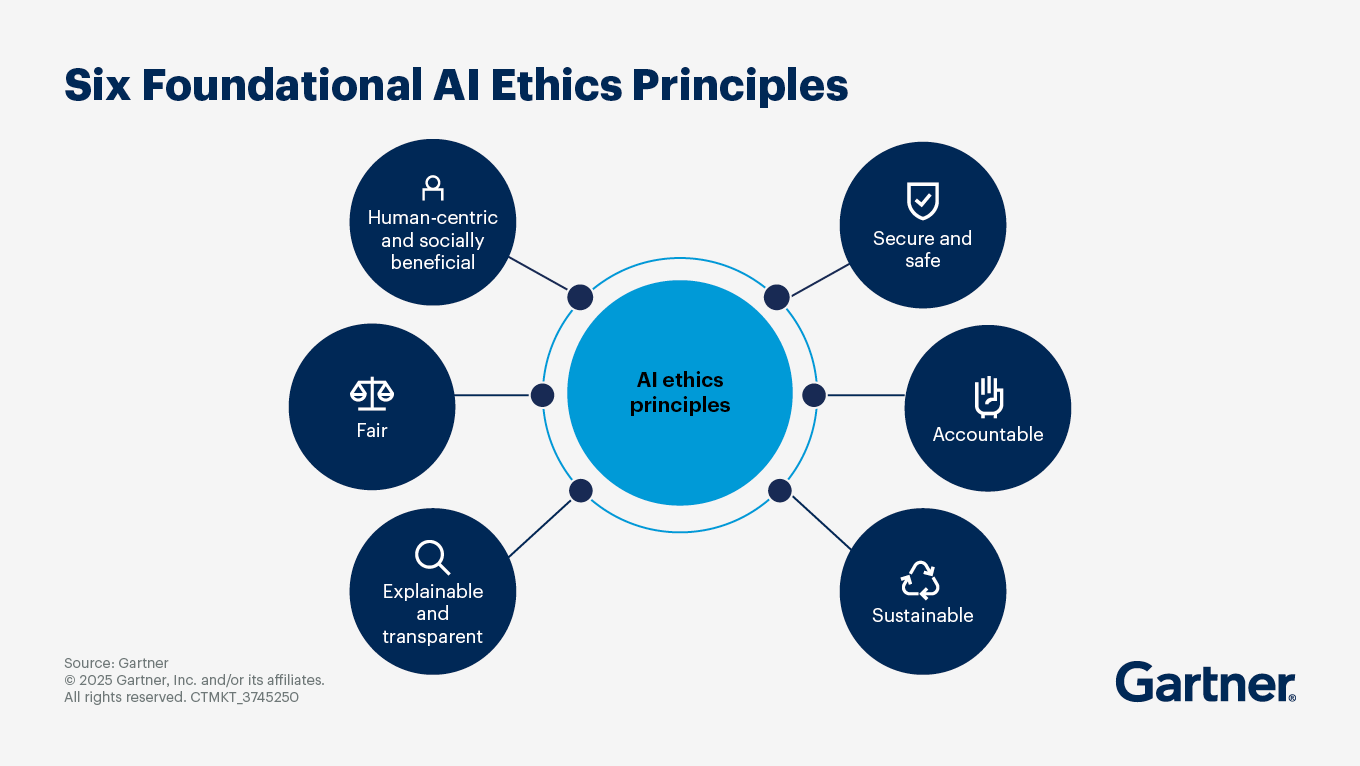
What is the business value of AI ethics?
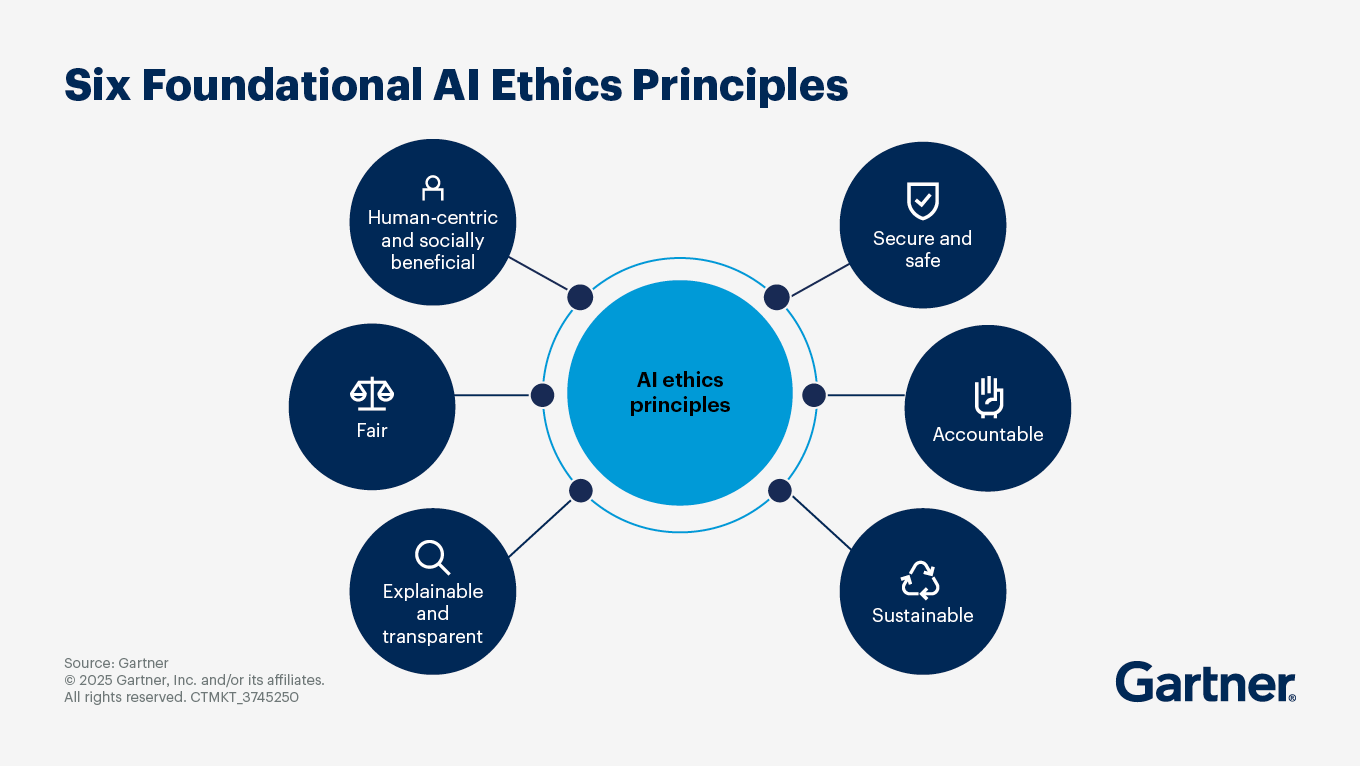
The business value of AI ethics is increasingly recognized among organizations leveraging AI. Each of its principles relate to business benefits:
Human-centric and socially beneficial: Implementing ethical AI practices helps build trust with customers, employees and investors. Organizations that prioritize ethical considerations in their AI initiatives are more likely to maintain a positive reputation, which can boost customer loyalty and strengthen the brand.
Fair: Fairness includes bias mitigation, which helps with regulatory compliance. Furthermore, when customers feel they are treated fairly, based on their specific circumstances, it can positively affect retention.
Explainable and transparent: When you understand what your AI is doing, you are more confident in bringing it to market. This also positively affects the organization’s risk metrics, such as reputation risk.
Secure and safe: The business value is in data security, privacy metrics and operational risk.
Accountability: Strong AI governance facilitates shorter time to response and lower cost of compliance.
Sustainability: Efficient use of resources and alignment with an organization’s ESG goals is cost effective.
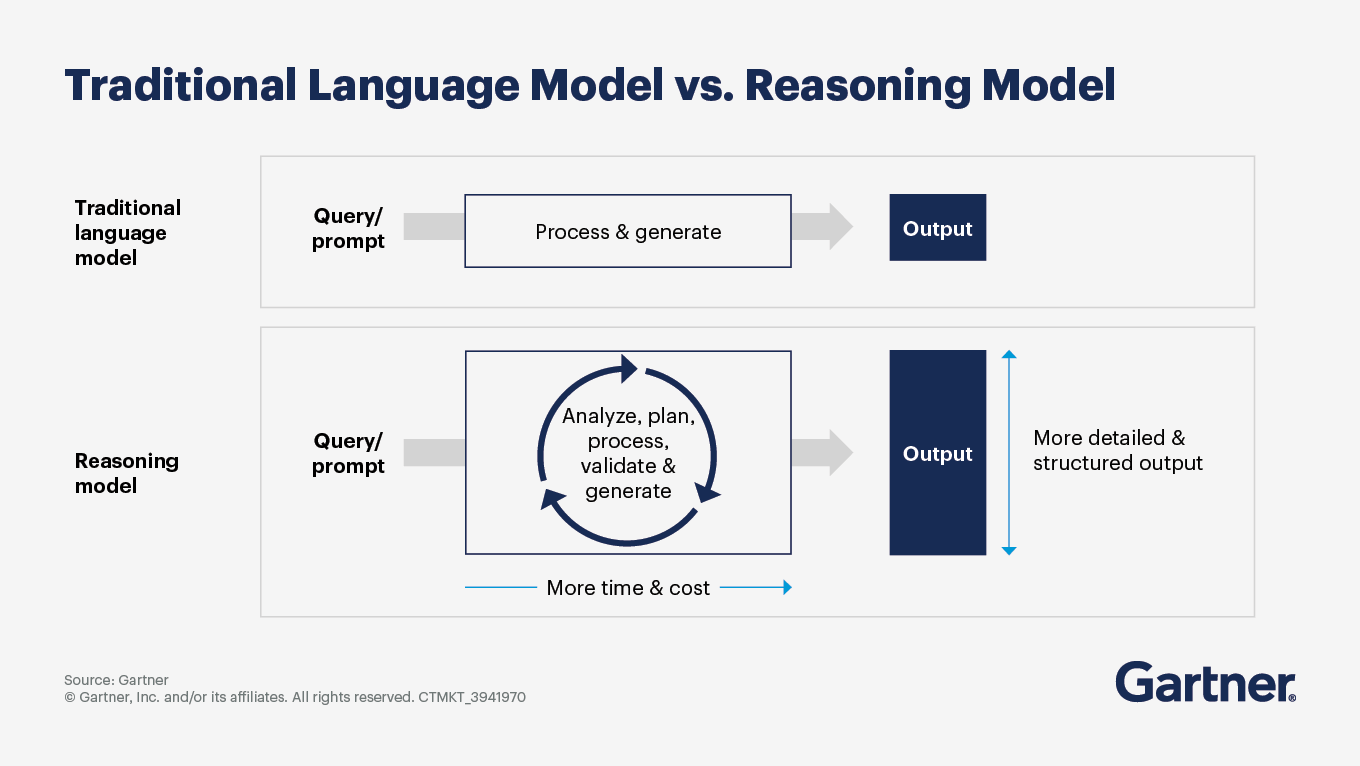
Where do I apply enhanced reasoning language models? Do I need to use them to upgrade all my GenAI use cases?
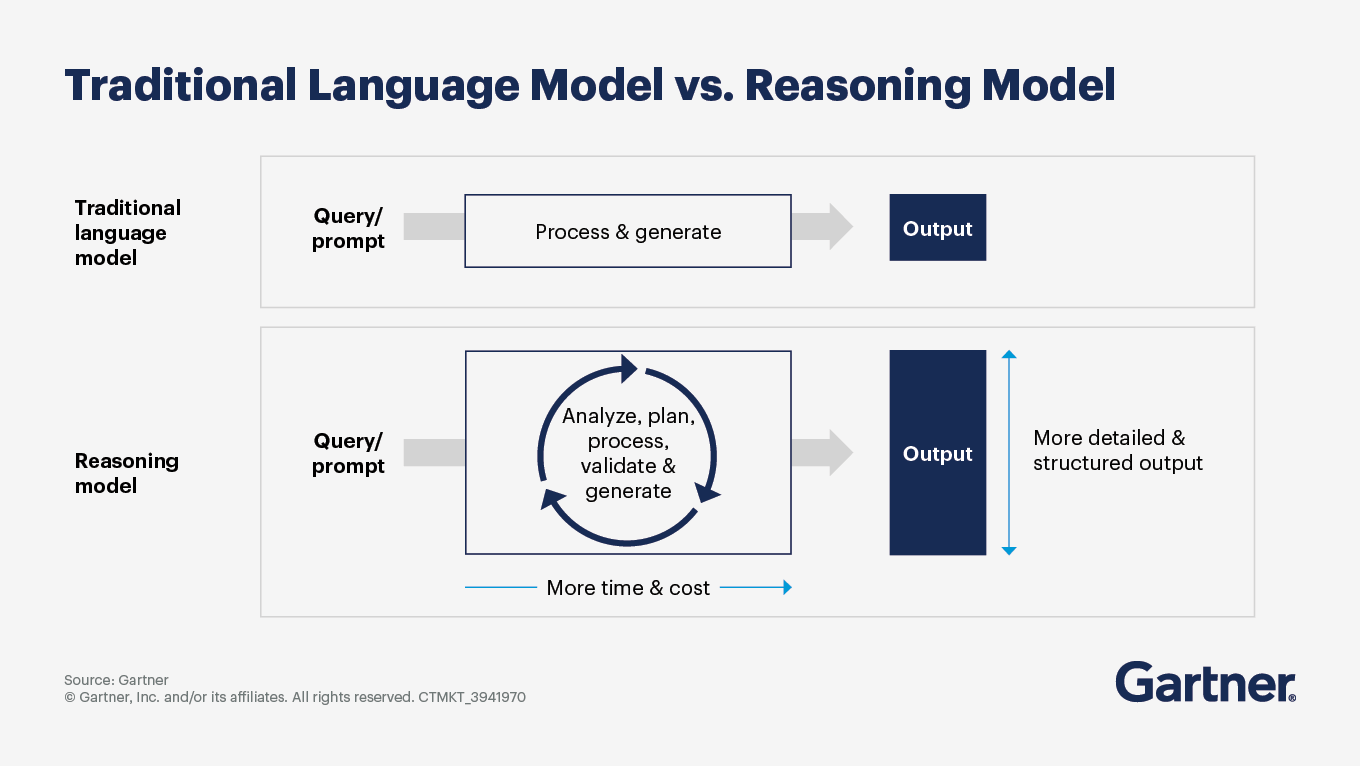
Enhanced reasoning language models (RMs) are designed to tackle complex tasks that require logical inference, multi-step reasoning and structured outputs. The best applications for these models include:
Providing explainable and structured outputs: RMs provide visibility into AI’s decision process and generate clear explanations of complex analysis or decision logic.
Analyzing extensive and complicated information: These models can review and assess vast document sets, generate comprehensive summaries and facilitate complex code analysis, comprehension and refactoring.
Tackling complex technical and logical problems: RMs excel in scenarios that involve intricate decision-making processes, such as regulatory compliance checks, financial risk analysis and medical diagnostics.
Automating workflows and using tools: These models can coordinate the specialized skills of individual AI agents to collaboratively execute multistep processes, connect and interact with enterprise systems and integrate real-time external information retrieval.
While enhanced reasoning models offer significant advantages, not all generative AI use cases should be upgraded with them. Here are some considerations:
Complexity of use cases: For simple tasks that do not involve multiple steps and require elaborate outputs, traditional large language models (LLMs) may suffice.
Resource requirements: RMs typically consume a lot of computational resources and time due to their planning and validation processes. For applications where speed and efficiency are critical, traditional LLMs might be more appropriate.
Current limitations: While RMs show promise, they are still maturing. Their performance can vary, and they may not always provide the desired accuracy or reliability.
August 2025
What should I know about GPT-5?
OpenAI’s GPT-5 introduces a modular architecture that blends fast-response models with deep reasoning capabilities, improving coding accuracy, multimodal performance and enterprise efficiency. It features expanded context windows, dynamic model routing and safer completions, making it a strong candidate for tasks like document automation, customer service and software development. However, GPT-5 is not a breakthrough in artificial general intelligence (AGI) and still requires strong governance, integration planning and human oversight.
Leaders should treat GPT-5 as a strategic upgrade — not a silver bullet. It’s best deployed in controlled environments to benchmark performance and assess ROI. Organizations must update governance frameworks to reflect GPT-5’s new behaviors and optimize cost-performance by experimenting with model sizing, reasoning parameters and caching strategies.
July 2025
What are the benefits and risks for organizations pursuing an agentic AI strategy?
By Gene Alvarez

While an agentic AI can provide significant advantages in terms of efficiency, decision making and innovation, organizations must also be aware of the associated risks, particularly regarding data quality, security and employee acceptance. A balanced approach that includes robust AI governance, risk management and employee engagement is crucial for successfully leveraging agentic AI technologies.
The top benefits of pursuing an agentic AI strategy include:
Faster and more informed decision making: Agentic AI can autonomously analyze complex datasets, identify patterns and make choices.
Increased efficiency: By automating routine tasks and workflows, such as processes in logistics, customer service and supply chain management, agentic AI can significantly reduce operational costs and improve productivity.
Scalability: Agentic AI systems can handle increased workloads without a proportional increase in human resources.
Upskilling the workforce: Agentic AI can empower employees by enabling them to manage complex processes through natural language interfaces.
Improved customer experience: AI agents can provide personalized interactions and support and enact tailored marketing strategies.
Innovation and competitive advantage: By leveraging agentic AI, organizations can adapt to market changes quickly and maintain a competitive edge in their industries.
The major risks of pursuing an agentic AI strategy include:
Data quality and integrity issues: Poor data quality can create inaccurate outputs and decision-making errors, which can have significant operational impacts.
Lack of human oversight: This can lead to uncontrolled actions and compliance issues.
Integration complexity: Integrating agentic AI into existing systems may require significant and disruptive changes to infrastructure and workflows.
Security and privacy risks: New security vulnerabilities include data breaches and unauthorized access to sensitive information.
Regulatory and compliance challenges: Organizations must navigate a complex landscape of regulations regarding AI use, data privacy and ethical considerations. Noncompliance can lead to legal repercussions and reputational damage.
Resistance to change: Employees who fear job displacement, or lack understanding of the technology, may be hesitant to adopt agentic AI, hindering successful implementation and usage.
What are the most common use cases for DSLM (domain-specific language models)?
By Alizeh Khare
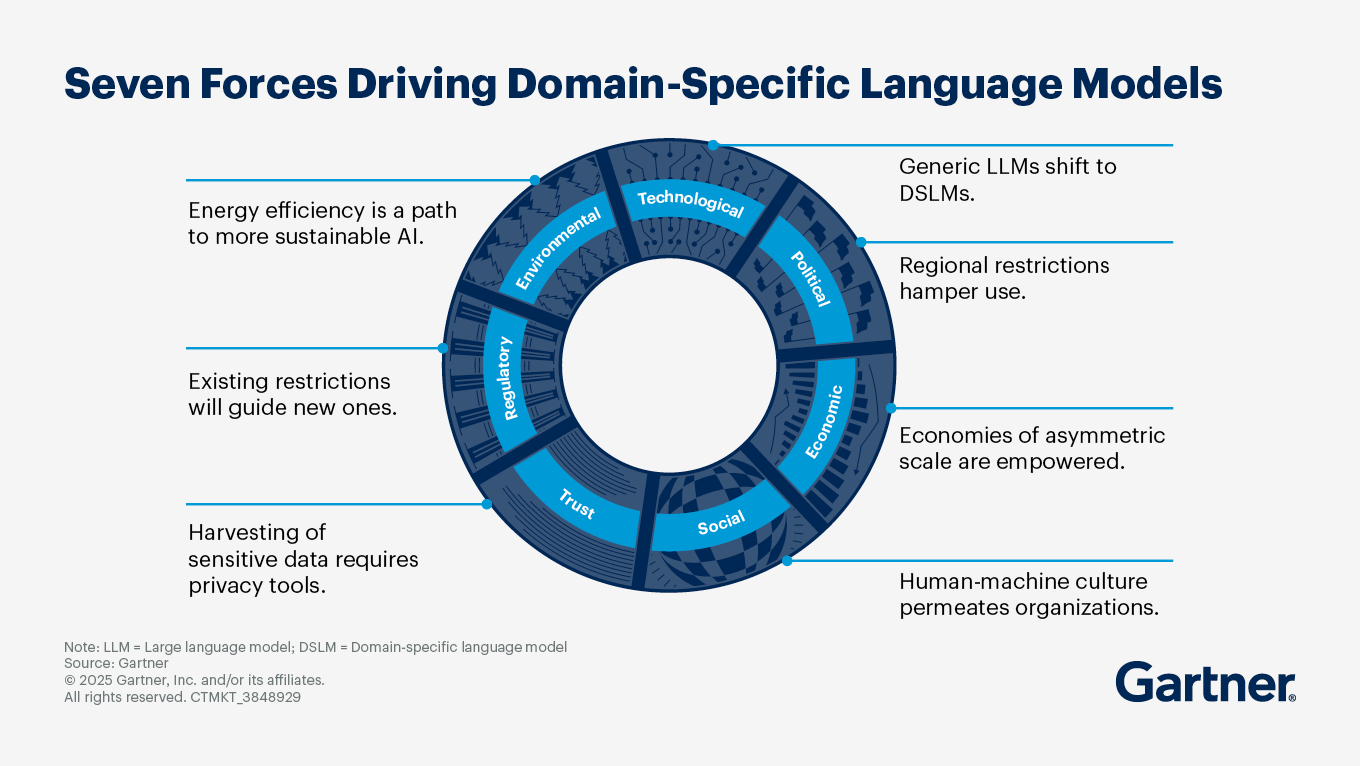
Organizations across industries are increasingly adopting domain-specific language models (DSLMs) to provide tailored solutions that address specific business needs. Common use cases include:
Writing and text generation: Sixty-nine percent of tech providers are developing DSLM solutions to create blog posts, product descriptions, legal documents and technical manuals.
Knowledge management: DSLMs enhance knowledge retrieval and facilitate efficient question-and-answer sessions within specific domains, improving collaboration and decision-making processes.
Conversational AI: DSLMs empower chatbots and virtual assistants to provide contextually relevant responses, enabling better customer interactions and support.
Data analysis and insights: DSLMs can analyze domain-specific data to provide more relevant and accurate insights than those generated by general-purpose models. This includes applications in finance for fraud detection and in healthcare for patient data analysis.
Compliance and regulatory tasks: In highly regulated industries such as finance and healthcare, DSLMs help automate compliance-related tasks, ensuring that organizations adhere to legal standards while improving operational efficiency.
Semantic tagging and classification: DSLMs enhance data organization through semantic tagging, which improves the accuracy of information retrieval and categorization.
Personalized recommendations: In retail, DSLMs can provide personalized product recommendations based on customer behavior and preferences.
Translation and summarization: This is particularly useful in industries that require multilingual support and quick information dissemination.
Healthcare applications: DSLMs can be used to generate clinical notes and assist in diagnostics, which can significantly improve patient care and operational efficiency.
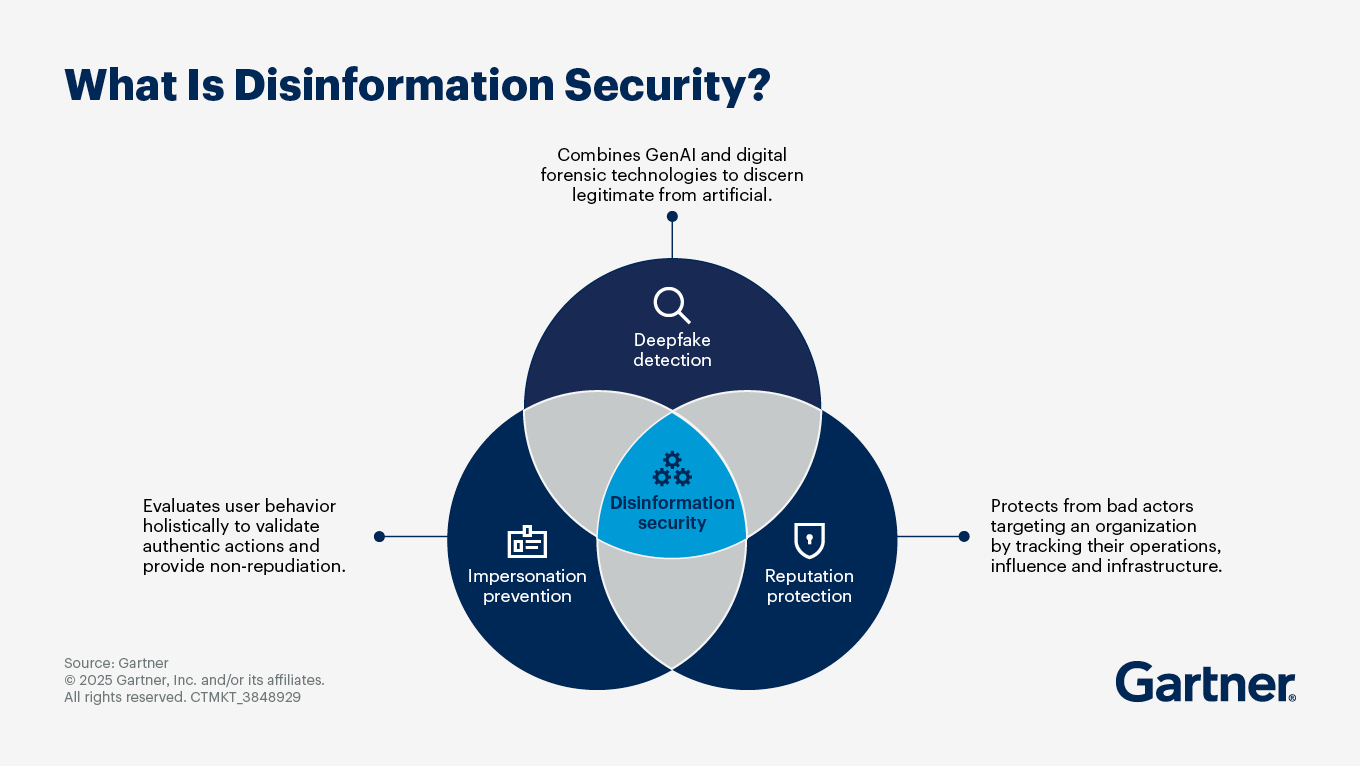
How can I use technology to combat disinformation risk?
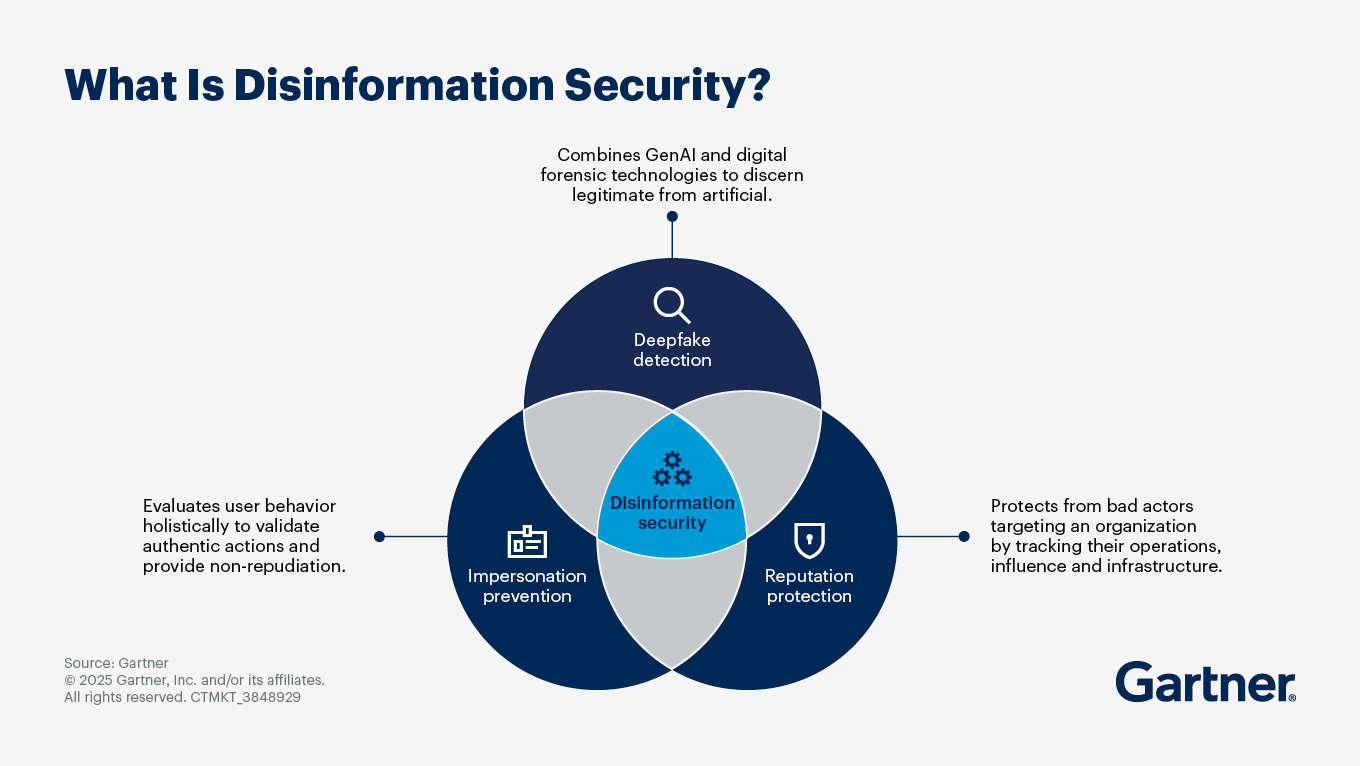
Consider these key technologies to establish disinformation security:
Deepfake detection: Effective deepfake detection requires a comprehensive approach that combines digital forensics, AI techniques and continuous updates to adapt to evolving threats.
Impersonation prevention: These technologies continuously evaluate user behavior across devices and interactions to validate authentic actions by incorporating continuous adaptive trust models. This mitigates risks associated with account takeovers and impersonation attacks.
Reputation protection: Narrative intelligence and media monitoring tools manage brand reputation by identifying harmful narratives and tracking their spread across various platforms.
Content verification technologies: These technologies assess the authenticity of content through fact-checking and verification processes. They can help organizations discern legitimate information from disinformation, especially in real-time communications.
Digital risk protection services: Monitoring external digital landscapes, such as social media and news platforms, allows these tools to identify and mitigate disinformation threats before they escalate.
AI-powered narrative monitoring: By analyzing narratives that spread through social media and other channels, this technology helps organizations understand public sentiment, identify potential disinformation threats and track the evolution of harmful narratives.
Identity verification solutions: Often with biometric authentication methods enhanced with liveness detection capabilities, these solutions ensure that the identities of users are accurately verified, especially in contexts where deepfakes and impersonations are prevalent.
Collaborative learning models: Federated learning approaches can train models on decentralized data without compromising privacy, allowing organizations to improve their disinformation detection capabilities while maintaining data confidentiality.
Why is photonic high-speed AI important for the future of artificial intelligence and computing?
By Alizeh Khare
Photonic high-speed AI is poised to play a transformative role in the future of artificial intelligence and computing by enabling faster, more efficient and scalable data processing capabilities, which are essential for meeting the growing demands of AI applications. Its significance is thanks to:
High-speed data transfer: Photonic interconnects use light (photons) for data transmission, enabling data rates of up to 4 terabits per second (Tbps). This capability is crucial for handling the massive data requirements of AI workloads, particularly in data centers where rapid processing and communication between components are essential.
Energy efficiency: Photonic systems are designed to consume significantly less power than traditional electrical interconnects. This reduction in energy consumption is vital as the demand for computational power increases, especially with the rise of AI applications that require extensive processing capabilities.
Scalability: The integration of photonic interconnects into computing architectures allows for greater scalability of compute clusters. As AI models grow in complexity and size, the ability to efficiently scale up resources without a corresponding increase in power consumption becomes increasingly important.
Reduced latency: Photonic technologies can significantly lower latency in data transmission, which is critical for real-time AI applications. This improvement in speed and responsiveness can enhance the performance of AI systems, particularly in applications that require immediate data processing and decision making.
As photonic technology matures, it is expected to drive further innovations in AI and computing. The development of industry standards and reduction in manufacturing costs will facilitate broader adoption, making photonic interconnects a foundational technology for future AI systems.
To see previously featured answers to client questions on emerging technologies, visit the archive.
June 2025
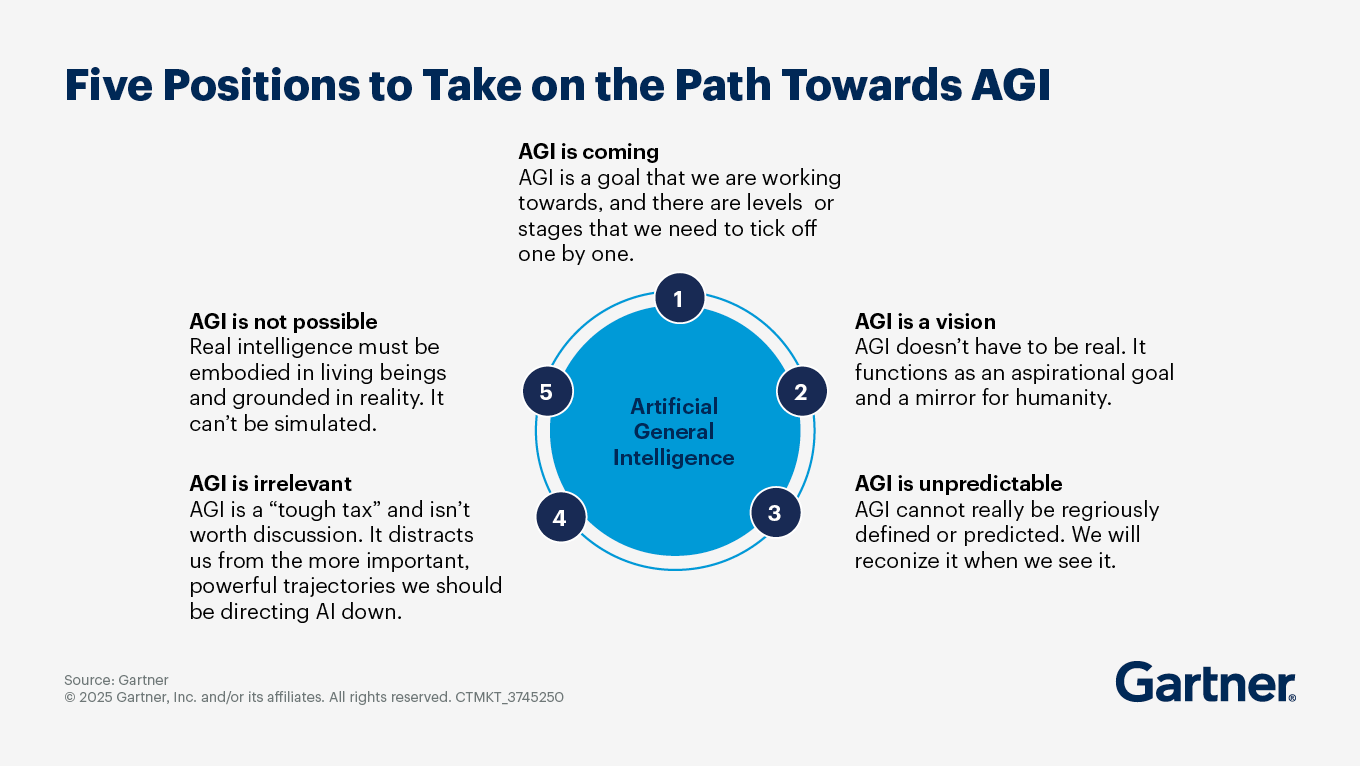
What is AGI (artificial general intelligence) and how does it differ from narrow AI?
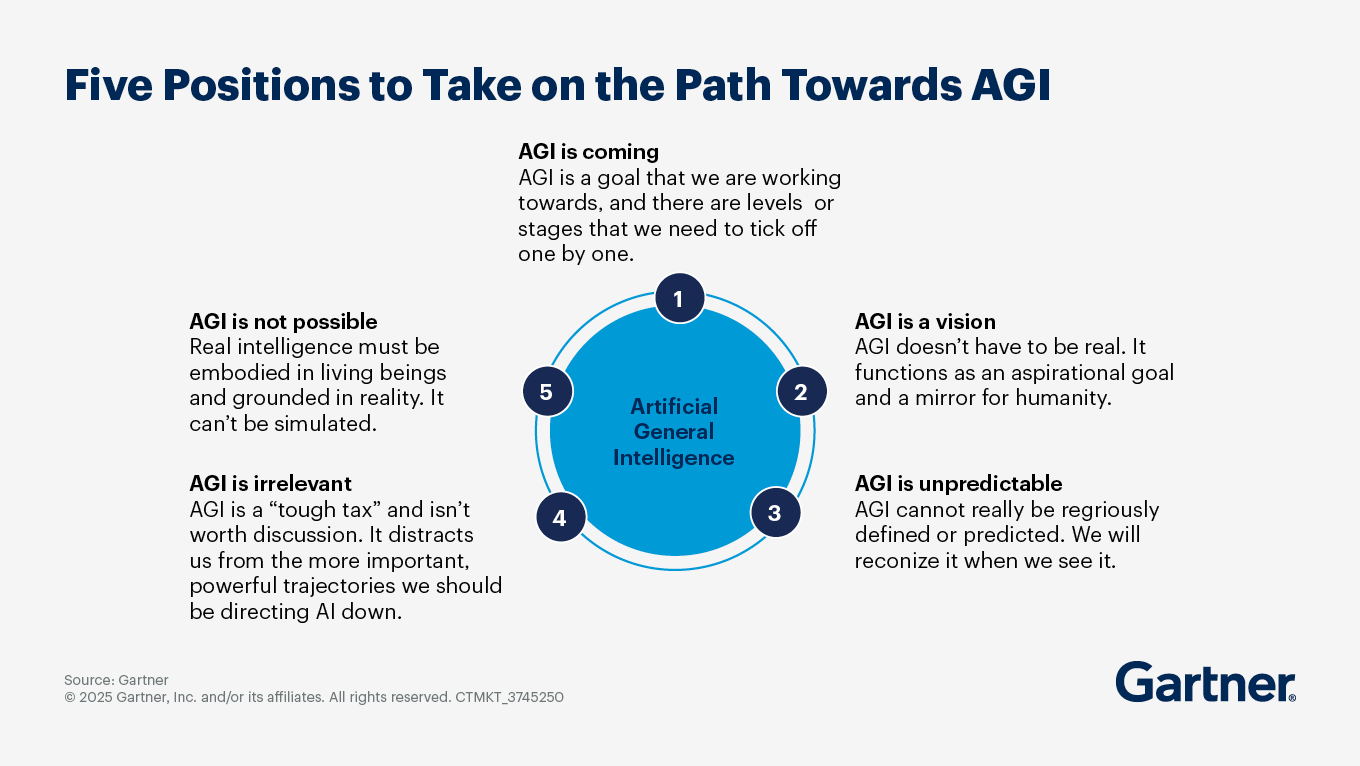
Gartner defines artificial general intelligence (AGI) as the (currently hypothetical) capability of a machine that can match or surpass the capabilities of humans across all cognitive tasks. In addition, AGI will be able to autonomously learn and adapt in pursuit of predetermined or novel goals in a wide range of physical and virtual environments.
Narrow AI is designed to perform specific tasks (such as image recognition, language translation or playing chess) or solve particular problems. Narrow AI systems rely on supervised learning and are limited to the data they are trained on. They cannot learn or adapt beyond their specific programming and training, making them less flexible in unfamiliar situations.
AGI is currently theoretical — no existing systems embody AGI capabilities. While the pursuit of AGI is often associated with ambitious goals in AI research and development, the technology raises significant ethical, societal and regulatory questions. Gartner’s position is that AGI will not be a reality in the next 10 years. Yet there will be progress toward AGI — and every step along the way can be turned into new types of business value.
AGI shouldn’t mimic human intelligence. It should, however, lead to new types of value. AGI also should not become a single-entity super intelligence, as technology should always support people in their endeavours. Should AGI appear, we believe it will be best achieved by connecting countless narrow AI agents to create a synergetic type of AI.
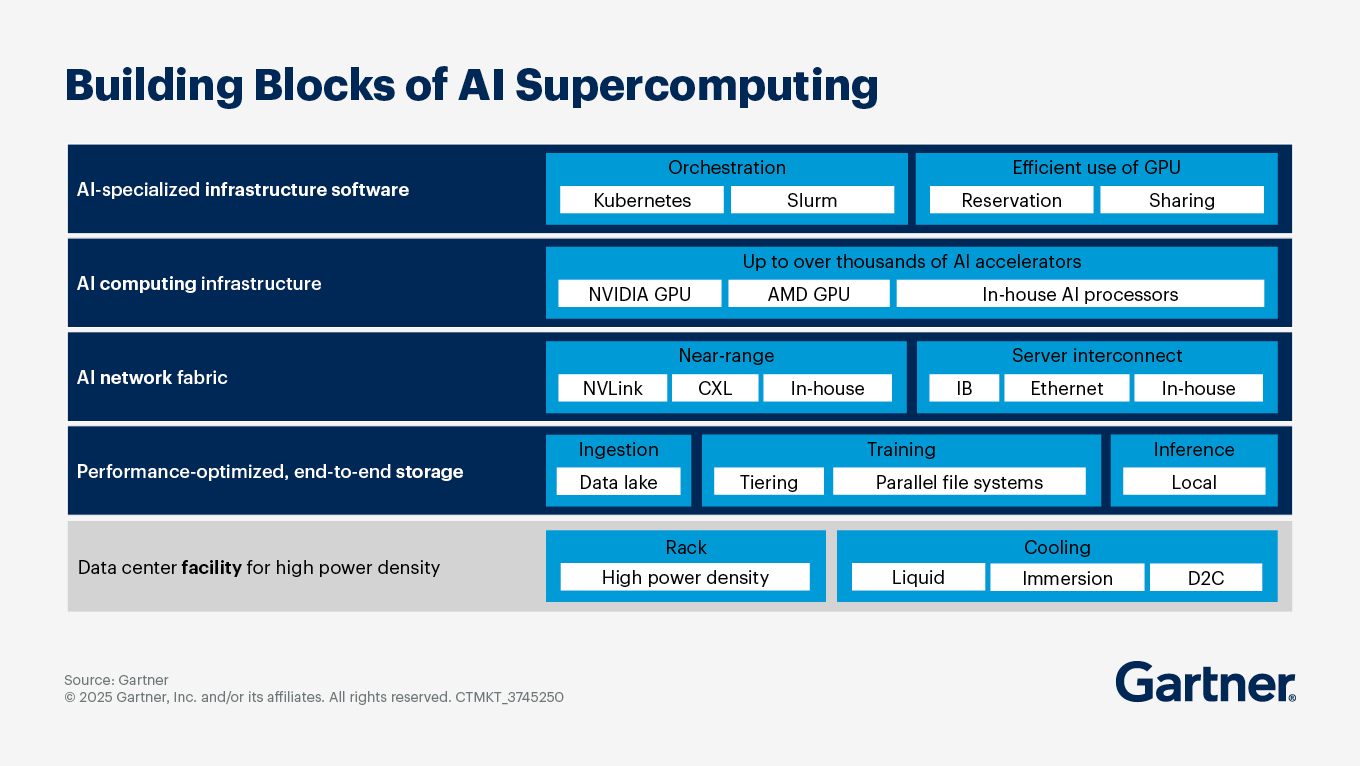
What investment in GPU infrastructure should I plan for to scale AI adoption over the next three years?
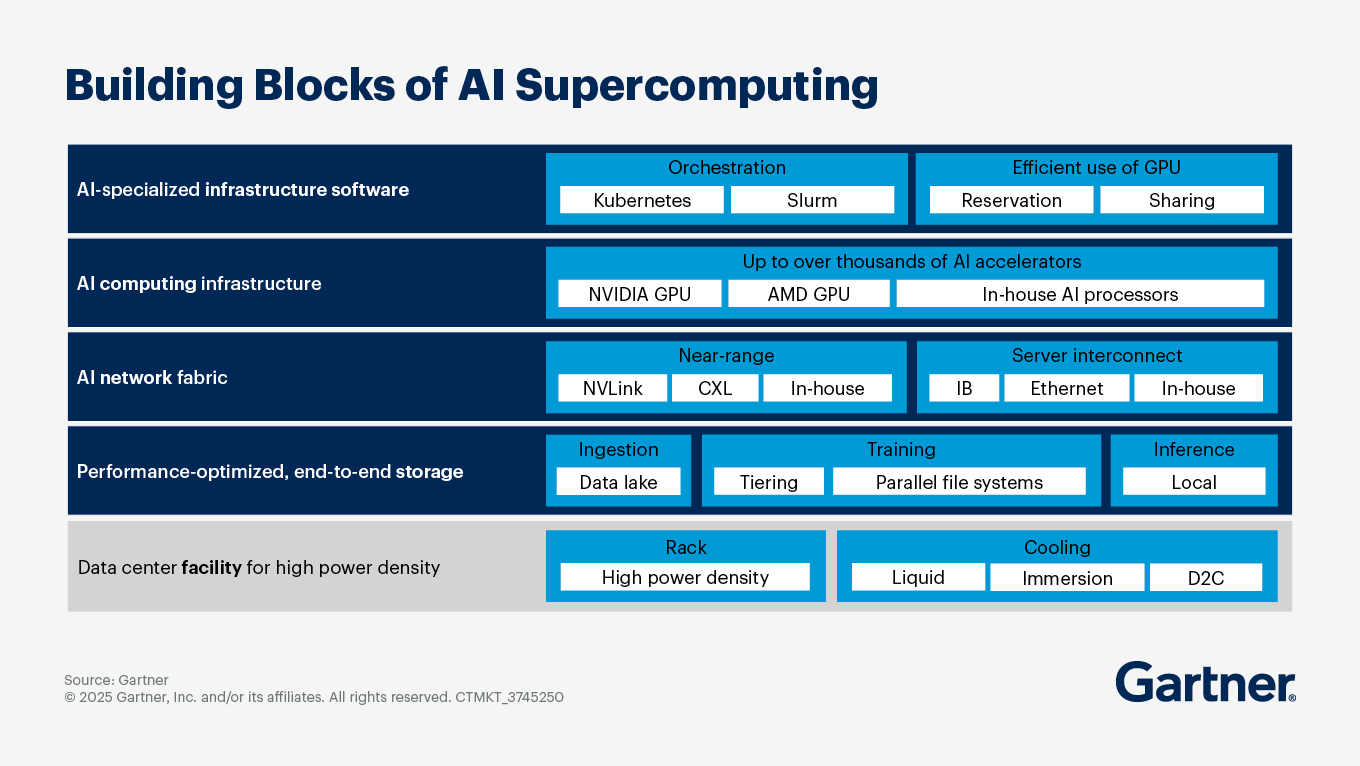
Consider a comprehensive investment strategy with five key components:
1. Infrastructure planning: Invest in AI-optimized infrastructure as a service (IaaS), which is projected to grow significantly over the next three years. This infrastructure should be designed to support AI workloads efficiently, leveraging cloud scalability and pay-as-you-go pricing models. Implement AI supercomputing architectures that integrate AI accelerators, optimized storage and high-speed networking. This architecture is crucial for handling the extreme-scale parallelism required for training generative AI models.
2. GPU acquisition and management: Use features like dynamic workload scheduling and GPU sharing to maximize the use of GPU resources. This is particularly important given ongoing GPU supply constraints and the increasing demand for inference workloads. Also reduce switching costs from traditional GPUs to cloud-optimized AI processors by investing in open standards and ecosystems.
3. Networking and storage enhancements: Build out dedicated networks for AI workloads, ensuring low-latency and lossless networking capabilities. This includes using InfiniBand or high-speed ethernet to connect GPUs effectively. Implement storage solutions that support high throughput and low latency, such as parallel file systems and object storage. These systems should be capable of handling the large datasets required for AI training and inference.
4. Cost management and efficiency: Integrate monitoring tools to track GPU usage and power consumption, which allows for better management of operational IT costs and efficiency gains. As AI workloads can significantly increase energy consumption, consider investing in advanced cooling technologies (like immersion cooling) to manage the high power density of AI computing infrastructure.
5. Training and skill development: Develop training programs for infrastructure and operations (I&O) teams to enhance their skills in managing AI infrastructure, including prompt engineering and AI data center design.
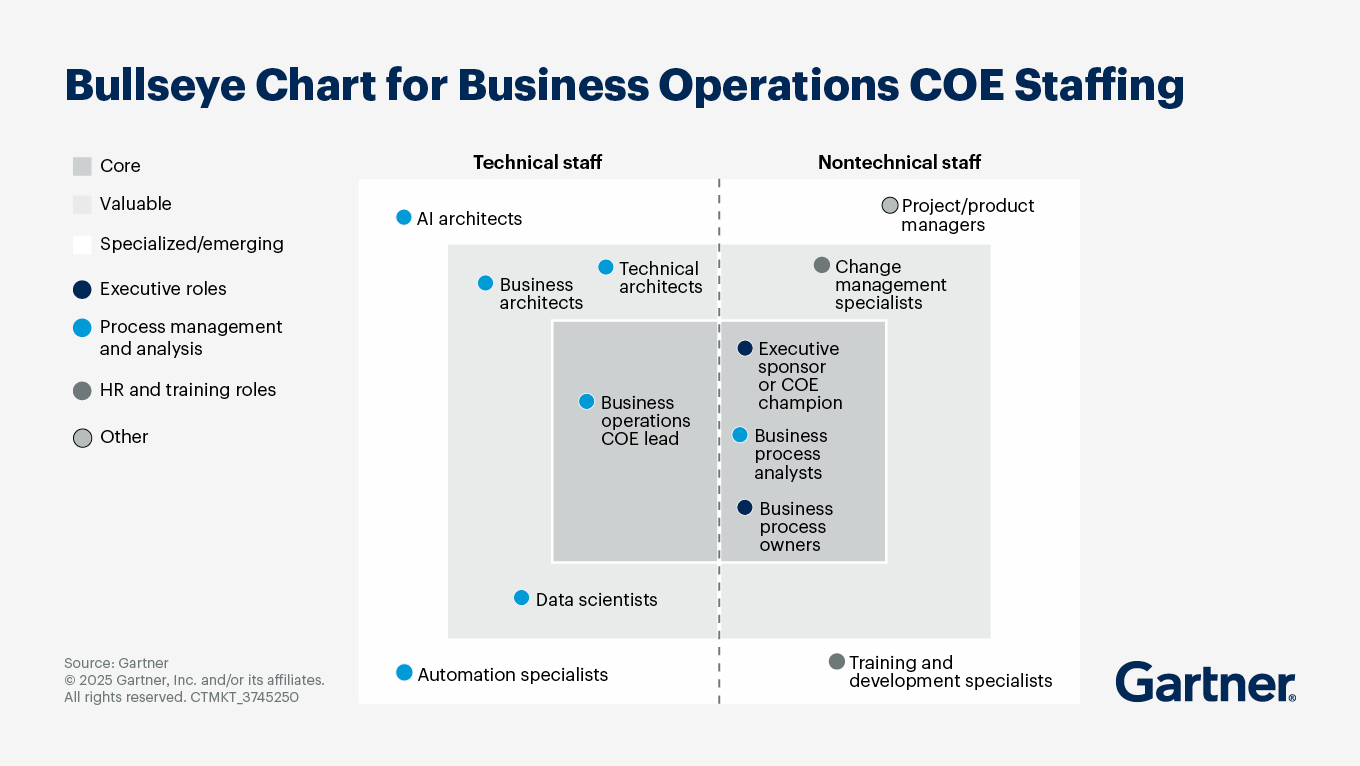
What is important to do when establishing an AI center of excellence (CoE)?
By Mordecai .
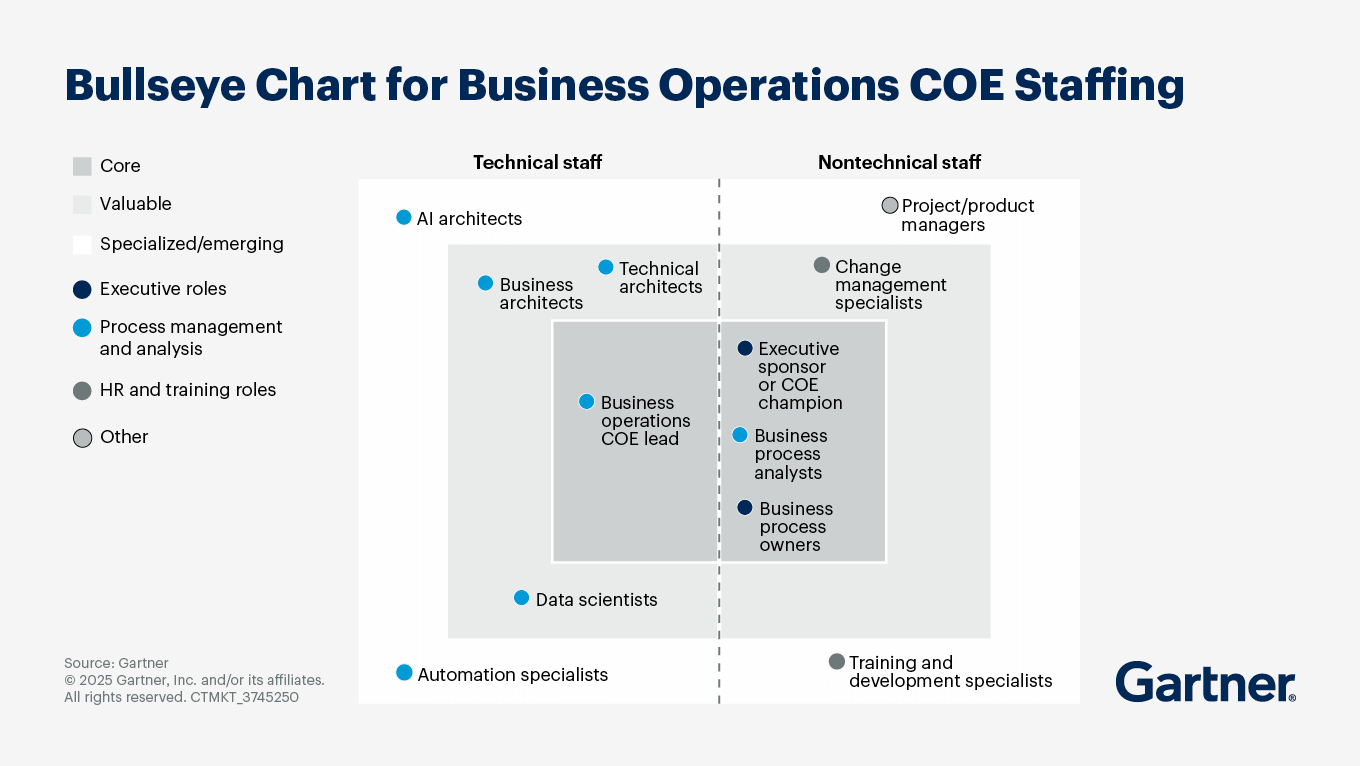
Establishing an AI center of excellence (CoE) is a strategic initiative that can significantly enhance an organization's ability to leverage AI technologies effectively. Important steps and considerations include;
Establish executive support: Secure an executive sponsor who will be actively involved in the CoE's projects and help navigate organizational challenges, and ensure the sponsor communicates the CoE's value to other business leaders.
Define CoE objectives and scope: Co-create a detailed charter that includes goals, principles, roles, metrics and communication procedures and aligns the CoE with organizational priorities Establish success metrics that are specific, measurable and relevant to leadership.
Assemble a diverse team: Ensure a generalist mindset is active and the focus not on the technology alone.Include those with a mix of technical and soft skills, such as AI architects, data scientists, and change management specialists, to manage designated activities effectively. Consider using consultants for initial projects to fill skills gaps and facilitate knowledge transfer.
Select impactful metrics: They should cover inputs, processes and outputs to provide a comprehensive evaluation of effectiveness, reflect organizational needs and link technology-driven metrics to business outcomes.
Determine the right organizational structure: Choose a model that can evolve as the enterprise matures. Common models include centralized, decentralized and federated structures.
Foster a culture of continuous improvement: Implement training and development programs to enhance the skills of CoE staff. Create recognition programs to celebrate successes and encourage engagement.
Leverage existing resources and tools: Conduct a thorough assessment of the existing IT landscape to identify tools that can be leveraged for AI initiatives. Establish partnerships with technology vendors to enhance the CoE's capabilities.
Create knowledge platforms (Innovation as a Service): Hub playbooks, technical guides, basic knowledge, and key use cases for access across the enterprise.
Monitor and evaluate effectiveness: Conduct surveys to gather insights on the CoE's impact and areas for improvement. Focus on measures that go beyond or are the result of increased productivity and efficiencies. Report metrics and success stories to senior leaders to secure ongoing support for the CoE.
Can I trust AI-powered robots to perform essential functions safely?
There is a lot of distrust around AI due to the incidence of a "black box" effect — we see results but cannot understand how they were arrived at. Lack of AI trust, risk and security (AI TRiSM) is further exacerbated by the lack of visibility in the underlying data that AI models used to create their results. AI-powered robots ultimately need humans to take accountability such that they perform their functions in a safe, secure, fair and socially beneficial manner.
Whether evaluating AI-powered robots or other AI use cases, Gartner recommends:
Collaborating with relevant stakeholders — enterprise architecture, IT, HR, legal and data analytics leaders — to embrace the potential of enhanced ethical AI governance platforms. Operationalize the key foundational principles of ethics and embed them in the broader AI strategy.
Addressing ethical dilemmas around the use and development of AI systems by adding an AI ethicist to the AI central team and/or forming a digital ethics advisory board to validate otherwise ambiguous AI outcomes and improve their contextual accuracy.
Continuously monitoring the behavior of AI systems by implementing a robust AI testing program, aligned with basic ethical principles to avoid potential negative consequences, such as legal backlash.
What is the maturity level and adoption roadmap for agentic AI?
As of now, only 6% of infrastructure and operations (I&O) organizations have achieved the highest maturity level necessary for the successful adoption of agentic AI. At most organizations, agentic AI is limited to isolated deployments that provide some benefits but are not transformative.
The adoption roadmap for agentic AI requires a structured, multi-prong approach:
Assessment and readiness: Begin by assessing your current state and identifying gaps in your infrastructure and operational models that may hinder the adoption of agentic AI. This includes evaluating data quality, governance and existing technology capabilities.
Strategic vision: Create a vision for agentic AI adoption that identifies constraints in decision-making and explores how these could be alleviated through agentic AI. This vision should align with the organization's overall IT operating model.
Investment in infrastructure: Focus future investments on ensuring that new infrastructure is compatible with agentic AI. This includes adopting intelligent infrastructures and platforms that can support the autonomous capabilities of AI agents.
Governance and management: Establish a governance framework that includes a Center of Excellence (CoE), staffed with IT professionals, business technologists and business leaders, to oversee the implementation and scaling of agentic AI initiatives.
Continuous improvement: Regularly reassess your AI maturity and adjust strategies based on evolving technologies and market demands. This includes refreshing the AI maturity assessment annually.
Implementation and iteration: After securing funding and developing a clear implementation plan, execute strategies iteratively.
April 2025
What is Manus AI? Can it be used for business applications?
By Daniel Sun
Manus AI, developed by the Chinese startup Monica.im and launched on March 6, 2025, is a general-purpose (large language model) LLM assistant with the potential to evolve into a general-purpose AI agent. It is a step up in AI technology, focused on enhancing human-machine collaboration and task automations of AI applications.
Key things CIOs should know about Manus AI
Capabilities: Manus AI offers a wide range of functionalities, including task automation, data processing, analysis and decision making and content generation. Manus AI can also learn from interactions and adapt its actions accordingly — for example by self-prompting tasks or modifying plans for a new context.
Technology: Manus AI leverages existing lLLMs, including Anthropic's Claude and Alibaba's Qwen, and employs a multiagent architecture. This allows it to utilize various tools and open-source software, enhancing its capabilities in task execution and interaction with APIs.
User Interface: A chatbot with a simplified user experience makes it accessible for users to interact with the AI while it manages tasks in the background.
Applications: The potential use cases of Manus AI for business include streamlining complex processes, enhancing customer engagement through automated responses and assisting in tasks like financial analysis.
Challenges: Operational stability can be an issue since Manus AI relies on third-party systems and APIs, which may pose risks in enterprise environments. Ethical and regulatory concerns also exist. These include questions of accountability and liability when AI makes critical decisions and uncertainty remains about its data sources and operational mechanisms. Its pricing is not clearly defined.
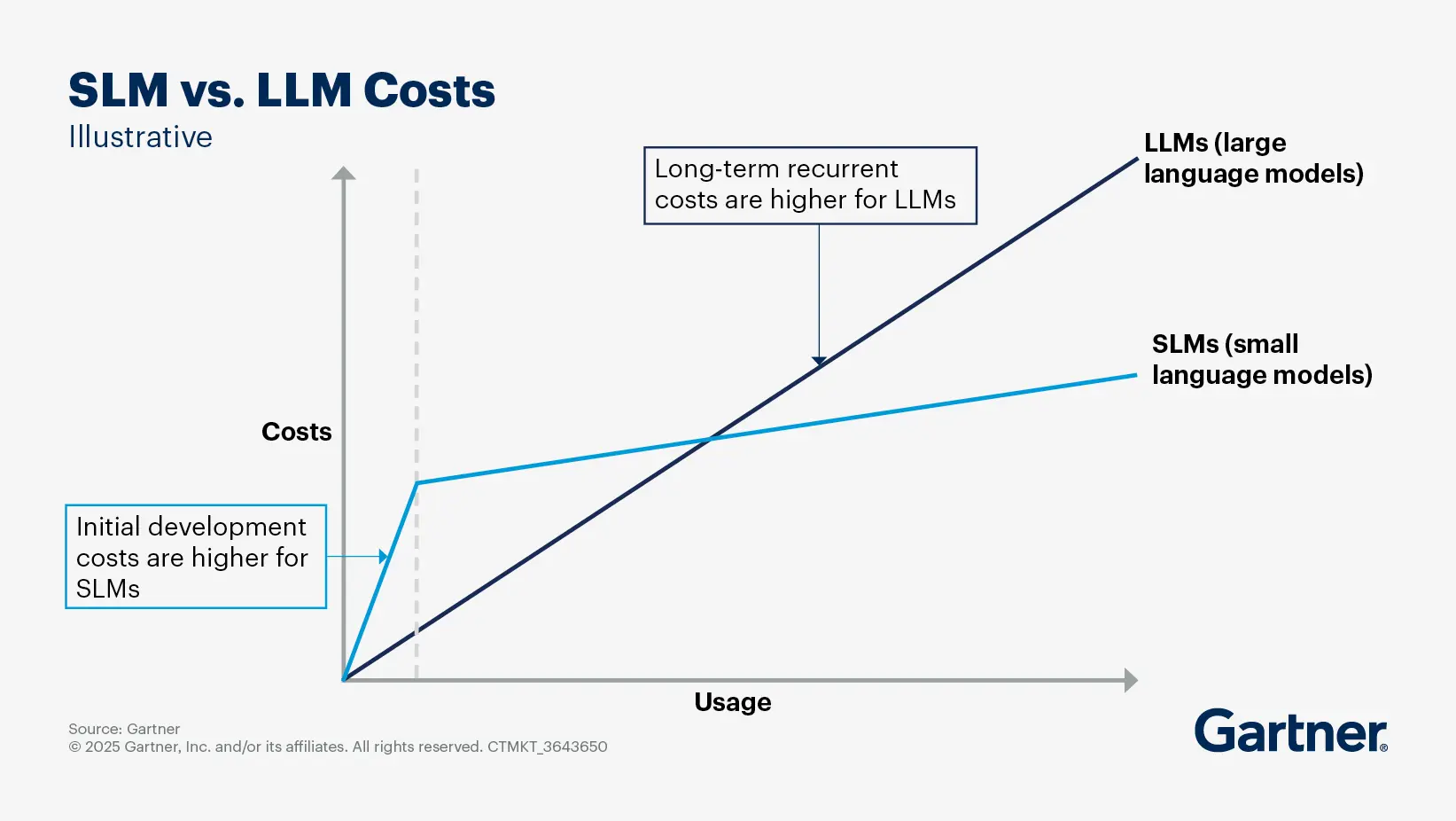
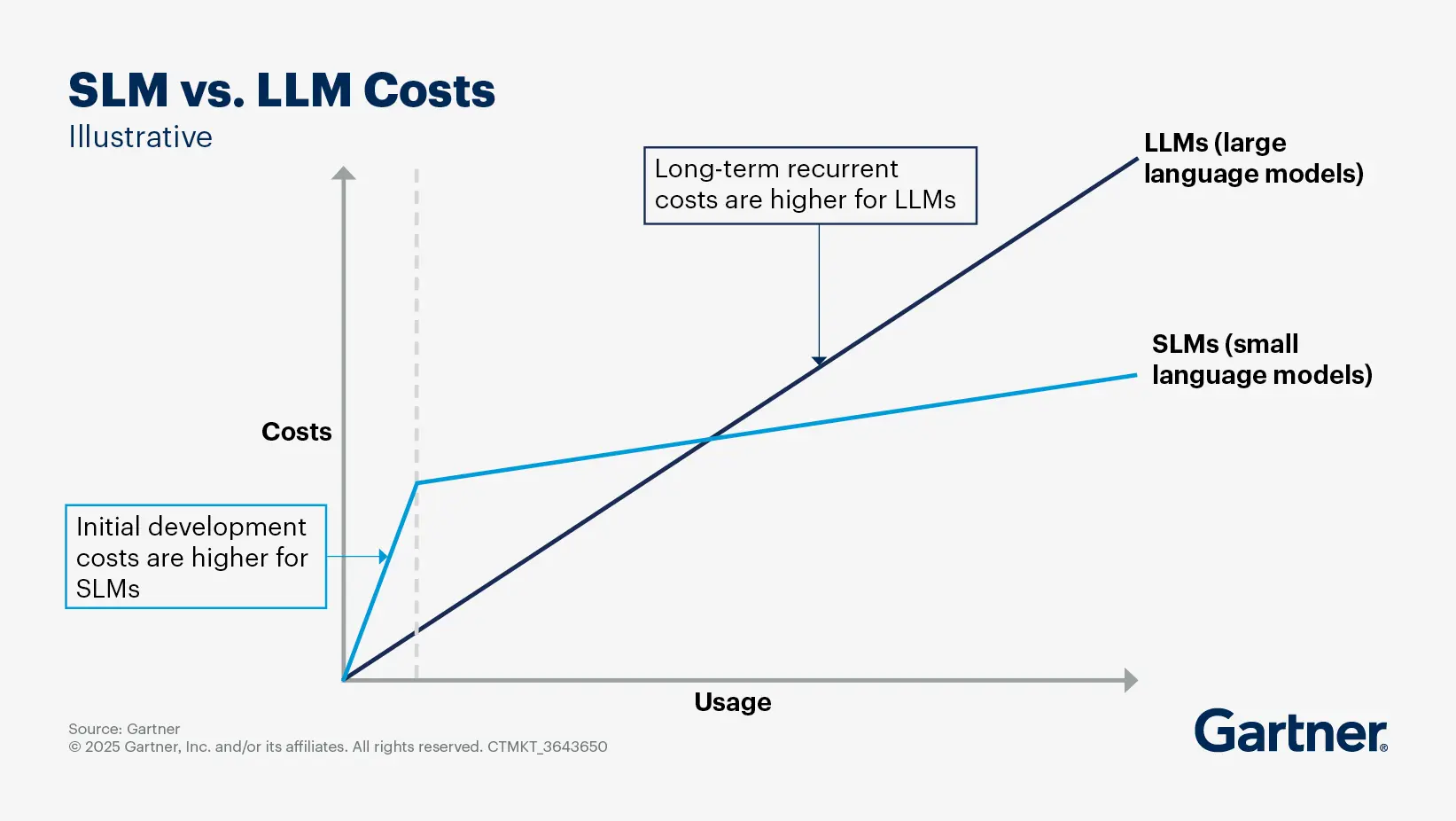
What are small language models? And how do SLMs compare with LLMs?
Small language models (SLMs) are a category of language models that are sized to be more efficient and cost-effective alternatives to large language models (LLMs).
SLMs are of the order of size of 10 billion parameters. Their strength is realized when tailored for specific tasks and domains. The smaller size makes them easier to fine-tune and deploy than their LLM counterparts.
Select advantages of SLMs
Cost-effectiveness: SLMs are relatively low cost to fine-tune and serve, making them suitable for organizations with budget constraints.
Efficiency: They require significantly fewer computational resources, which allows for deployment on-device, on-premises or in private cloud environments, enhancing data privacy and security.
Task specialization: When appropriately aligned to a specific use case and fine-tuned for that implementation, they can outperform larger models. This makes them particularly useful in scenarios where larger language capabilities are not necessary.
Use cases for small language models
SLMs are ideal for applications that involve high user interaction volumes, low-latency requirements, and sensitive data scenarios. They can be effectively used in document chatbots, customer service applications, and organizational language models.
They can also be integrated into multimodel systems, where multiple task-specialized models work together to address complex AI challenges.
SLMs vs. LLMs
While SLMs do not match the generic language reasoning and generation capabilities of LLMs, they excel in specific applications where their smaller size and lower resource requirements provide a significant advantage.
SLMs represent a practical and efficient approach to implementing generative AI solutions, particularly for organizations that require specialized capabilities without the overhead of larger models. For this reason, SLM adoption is expected to grow. Gartner projects that by 2026, more GenAI queries and requests will be processed on-device than in the cloud, enabling intelligent assistants and other proactive applications.
How is AI changing the landscape for edge devices?
Modern edge devices are becoming increasingly capable of running complex algorithms. At the same time, AI is being reshaped and adapted to the capabilities of those devices, allowing smarter, more efficient and autonomous applications. As AI models progress, we will see significant efficiency improvements in on-device inference with limited computational capacity and can expect even greater integration, driving innovation across various sectors.
Key impacts of AI on edge devices
Real-time processing: AI enables edge devices to perform real-time data processing and analytics locally, reducing latency and bandwidth usage and removing the dependency on network infrastructure. This is crucial for applications that require immediate decision making and robust processes, such as autonomous vehicles and industrial automation.
Privacy and security: By computing data locally, AI helps address privacy concerns, as sensitive information does not need to be transmitted to the cloud, but gets processed during runtime without storing raw data. This is particularly important for processing personal information, like biometrics, or in other heavily regulated industries where data sovereignty is a concern.
Integration with IoT: Edge devices are increasingly integrated into Internet of Things (IoT) meshes, allowing for smarter, more autonomous operations. Integrating AI onto the edge enables devices to learn from their environment and improve their performance over time, leading to more efficient operations and better user experiences.
Use of advanced techniques: Techniques such as TinyML, transfer learning and federated learning are being employed to optimize model training for edge devices. These advancements enable edge devices to perform machine learning tasks without needing extensive computational resources.
Cost efficiency: By reducing the need for data transmission to centralized systems, AI at the edge can lower operational costs long term, while initially increasing capital expenditures. This is particularly beneficial for applications that process large volumes of data, but only need to transfer a federated or aggregated summary, as bandwidth requirements and associated costs are minimized, compared to processing everything in the cloud.
Scalability and flexibility: AI enhances the scalability of edge solutions by allowing for distributed processing and decision making. New nodes on the edge can be applied without increasing the demand for scaling central IT structures significantly. This flexibility is essential for adapting to various use cases across different industries, from smart cities to health care.
Energy efficiency: Processing data directly on the edge device significantly reduces the overall energy consumption of the whole network infrastructure by minimizing unnecessary traffic or eliminating additional handling steps like safeguarding algorithms for sensitive raw data.
Flexible infrastructure: AI-powered edge devices can be part of larger composite structures to provide advanced functionalities via cloud-to-edge and edge-to-cloud integrations. This allows for synchronization with larger orchestrations while maintaining local execution.
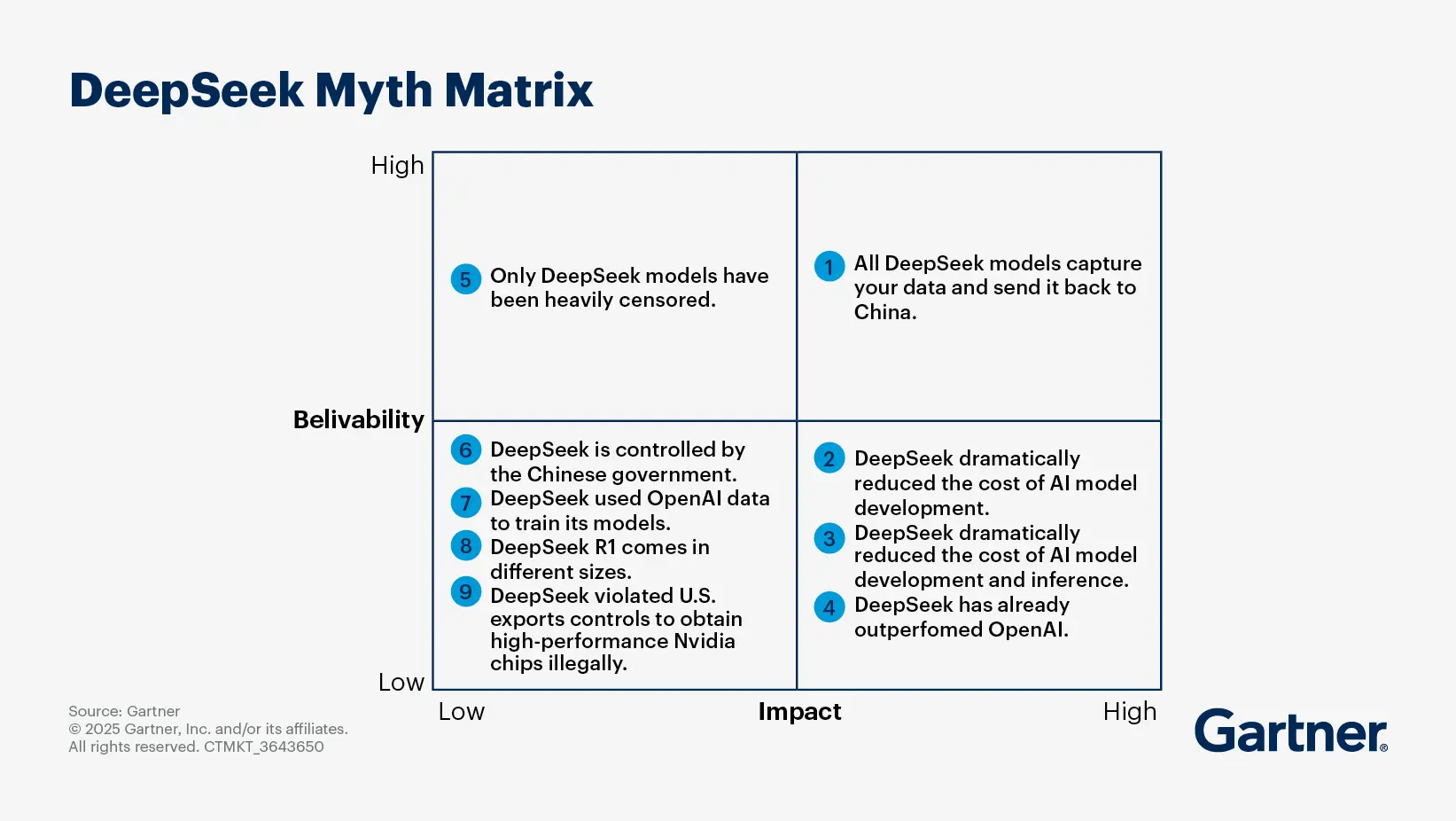
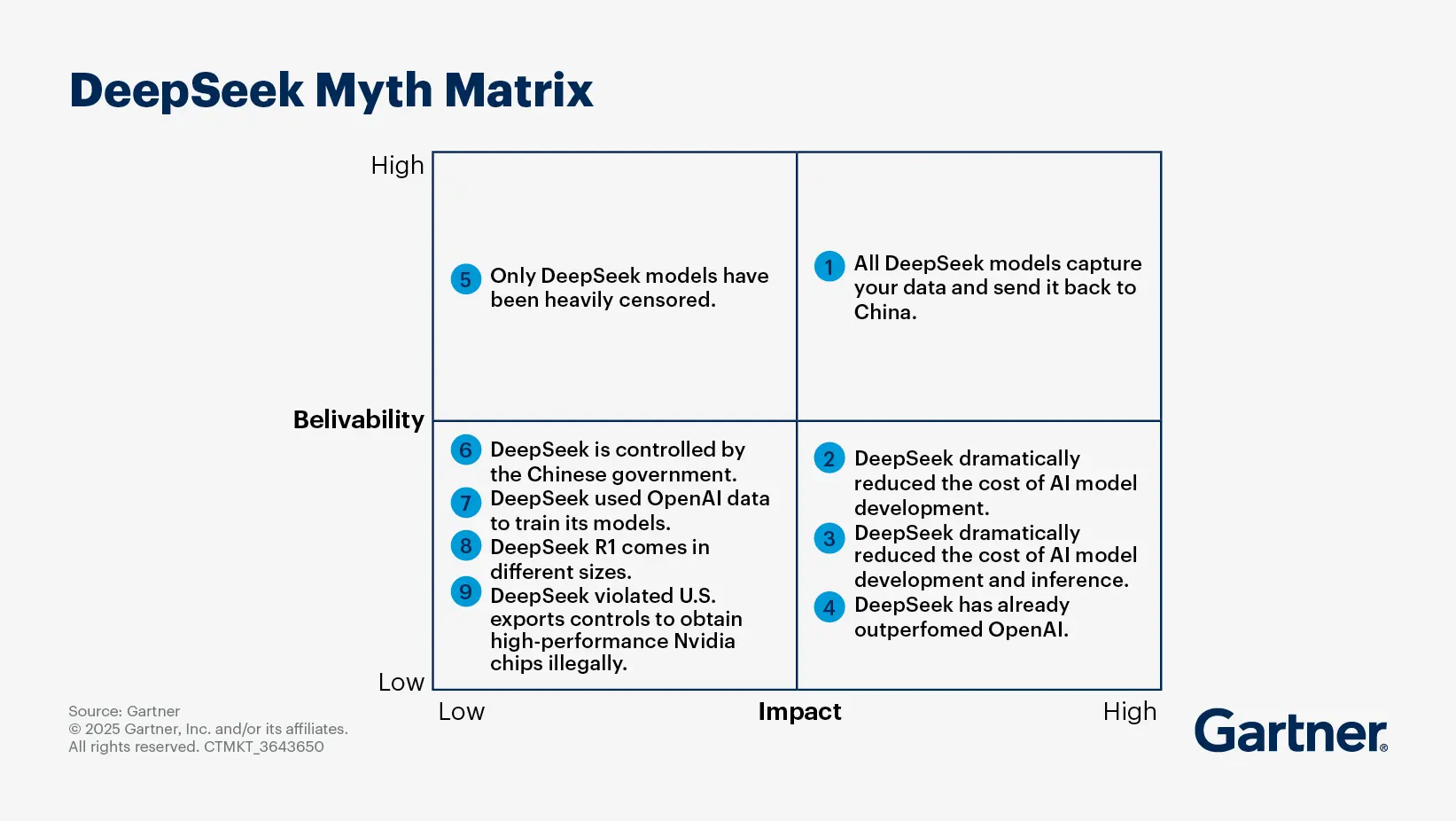
What is Deepseek R1 and why is it so innovative?
By Alizeh Khare
DeepSeek made a significant impact on the AI market in January 2025 with the launch of its R1 model, developed using distillation techniques.
DeepSeek R1 is a family of AI models focused on logical and reasoning tasks, available in two versions: DeepSeek R1, launched on January 20, 2025, and accessible on multiple platforms, and DeepSeek R1 Zero, which excels in accuracy and performance but is not yet released.
The architecture employs a mixture-of-experts (MoE) framework, activating only 37 billion of its 671 billion parameters per query, enhancing efficiency and resource conservation. According to DeepSeek, its R1 model is 20 to 50 times less expensive to use than OpenAI o1 model, depending on the task, and has dramatically smaller graphics processing unit (GPU) requirements.
DeepSeek’s models have demonstrated competitive performance, but the bold claims of cost and development efficiency haven’t been independently reviewed or validated. Still, the innovative approach and transparency allows researchers, competitors, and developers to understand both the strengths and limitations of the R1 model, which can potentially change the AI landscape by making it less expensive for providers to build and run AI models.
Use of open-source principles in DeepSeek model development
The techniques that DeepSeek used to achieve model-training breakthroughs are not proprietary. They are part of the open-source toolset and therefore available for other providers to study and learn from. This approach reinforces the notion that open-source AI is becoming more competitive with, and perhaps even surpassing, the closed, proprietary models of major technology firms.
The open source approach also aligns with the growing calls for ethical AI development, as it allows for greater scrutiny and accountability in how AI models are built and deployed.
Even with DeepSeek's assurances of robust data security, users are concerned about the management and potential sharing of their data. The absence of clear data-handling policies could undermine trust, particularly in regions with strict privacy regulations like the EU's GDPR, where DeepSeek faces scrutiny and restrictions from numerous companies and government agencies.
Still, the advancements made by DeepSeek could lead to a broader adoption of domain-specific AI models and a focus on sustainable AI practices.
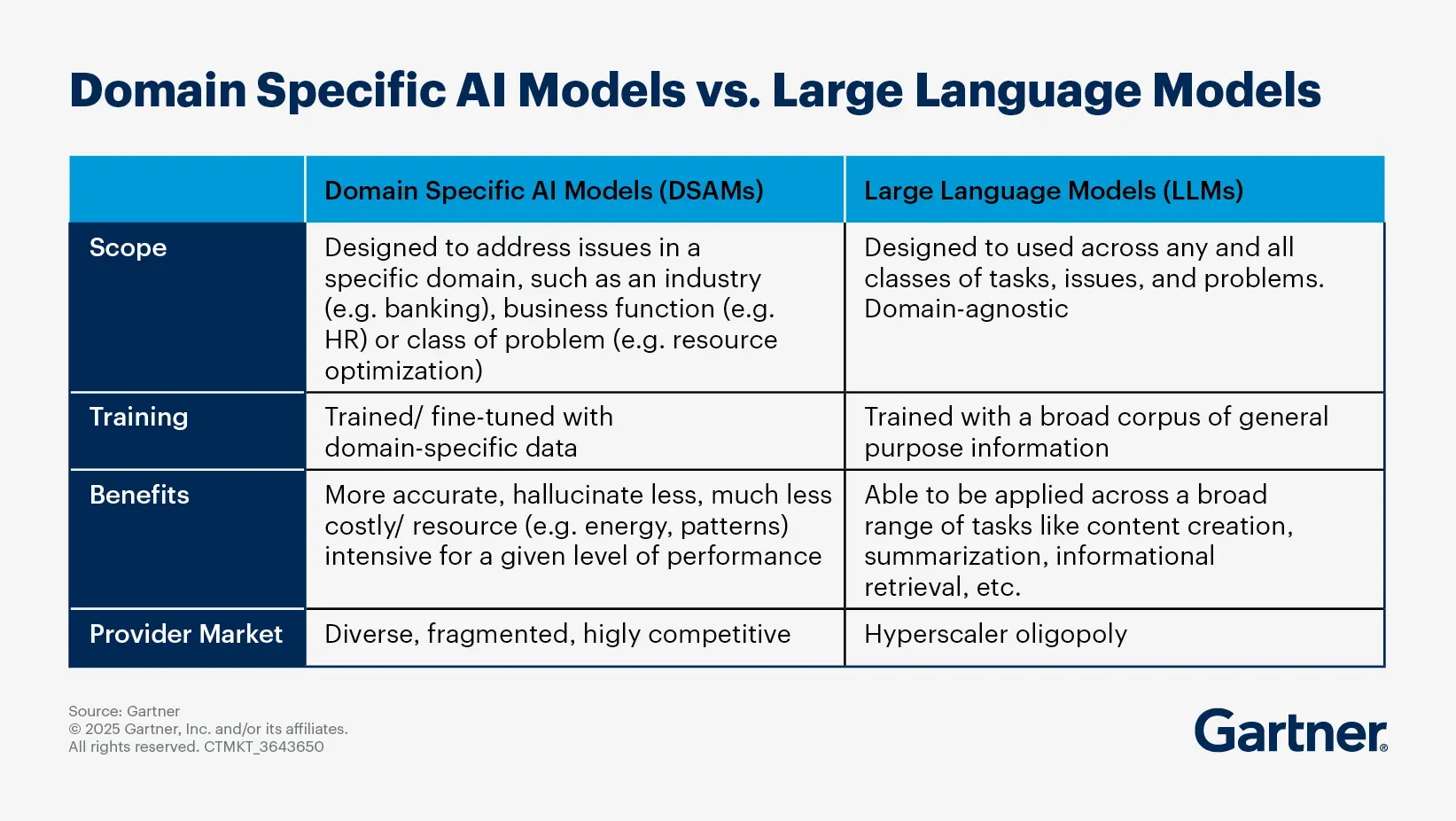
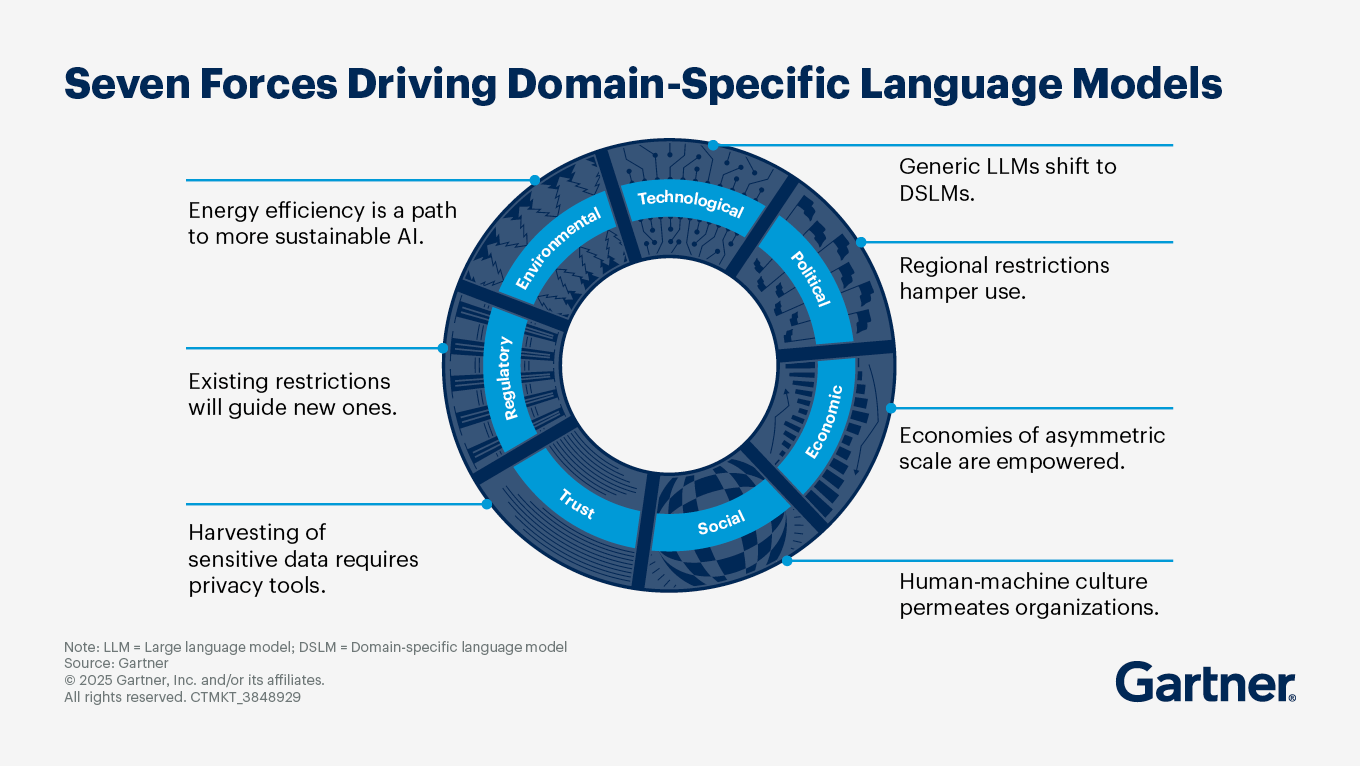
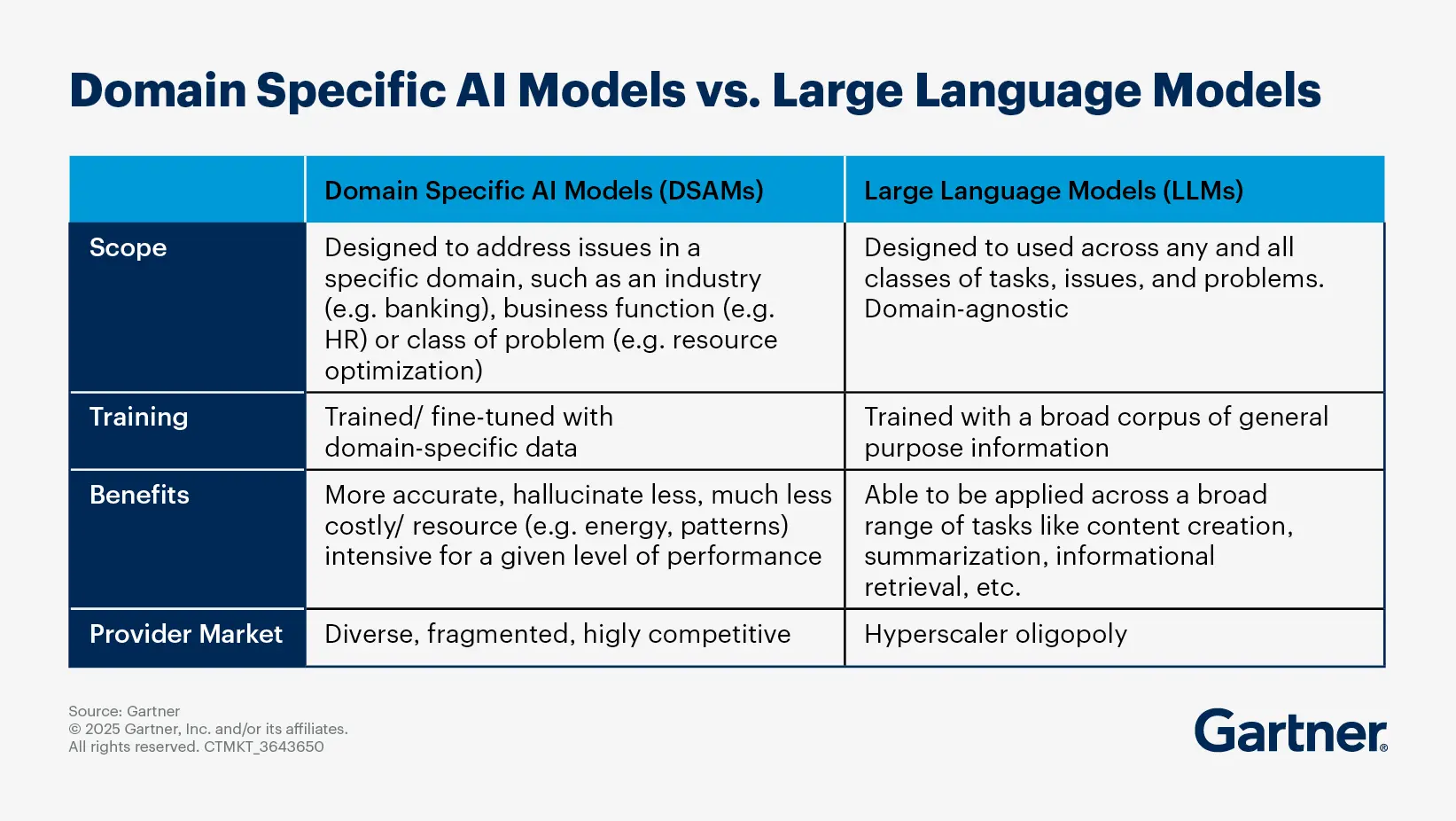
How do domain-specific AI models differ from generic LLMs for enterprises?
Domain-specific AI models (DSAMs) and generic large language models (LLMs) serve different purposes and have distinct characteristics that make them suitable for various enterprise applications. While LLMs are designed to be used across any and all classes of tasks, issues and problems in a domain-agnostic manner, DSAMs are designed to address issues in a specific industry, business function or a class of problem (resource optimization). Thus, the training methodology used and the benefits each brings will be distinct.
Key differences between domain-specific AI models and generic LLMs
Purpose and specialization
DSAMs: Tailored for specific industries, business functions, or tasks and optimized to understand and generate content relevant to particular domains, such as healthcare, finance, or legal sectors, providing greater accuracy, reliability, and contextual understanding.
Generic LLMs: Designed to handle a wide range of tasks across various domains, they excel in general language understanding and generation.
Training data
DSAMs: Often fine-tuned on datasets that are specific to their target domain, which helps them learn the nuances and terminologies relevant to that field. This reduces the need for extensive prompt engineering and enhances the model's performance in specific tasks.
Generic LLMs: Trained on vast amounts of unlabeled text data from diverse sources, which gives them broad capabilities.
Cost and resource efficiency
DSAMs: Tend to be more cost-effective for enterprises as they require less computational power and data for fine-tuning than generic LLMs, making them easier to deploy and maintain, especially in environments with limited resources.
Generic LLMs: Can be resource-intensive to deploy and fine-tune, requiring more parameters, energy, and higher cost to achieve the same performance level as DSAMs.
Use cases
DSAMs: Ideal for applications that require deep knowledge of a specific field, such as medical diagnosis, legal document analysis, or financial forecasting. They can provide more relevant and accurate outputs for these specialized tasks.
Generic LLMs: Suitable for a wide range of general tasks, such as content creation, summarization and information retrieval for conversational agents.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
What is model context protocol (MCP) and how does it enable AI agents?
By Gary Olliffe
As enterprises seek to implement AI agents that take on more complex tasks across workflows and processes, those agents will need to access a variety of data, information and functional resources. Model context protocol (MCP) is an open standard interface that defines a consistent and flexible way to connect AI applications and agents to these resources.
MCP defines how AI applications access and interact with other resources — such as information stores, APIs and other applications — in a model and application independent way. As AI agents evolve from isolated assistants into collaborative systems, they are increasingly relied upon to automate operations, augment productivity and support end-to-end business processes that require flexible integration.
Without MCP, each AI application framework or platform will define its own proprietary approach to connecting external resources to AI. With MCP, organizations will be able to share resources across a variety of AI use cases in a consistent and manageable way, reducing duplication and allowing developers and users to connect their AI applications to the most appropriate resources for a task or use case.
In software development, for example, agents will support tasks such as code modernization, test automation and issue resolution, ensuring each agent has the correct tools and context across stages is essential for efficiency and accuracy. MCP provides a standard mechanism for integrating these capabilities into off-the-shelf or custom-developed AI applications..
As AI agents become more autonomous and interdependent, IT executives should evaluate whether their AI architectures are designed to support flexible integration with shareable context. MCP is in the early stages of its lifecycle, and will need to mature rapidly to meet the enterprise needs, but its rapid growth in popularity highlights the demand for a standard interface for LLM-based AI applications and agents to connect to external context.
Drive stronger performance on your mission-critical priorities.